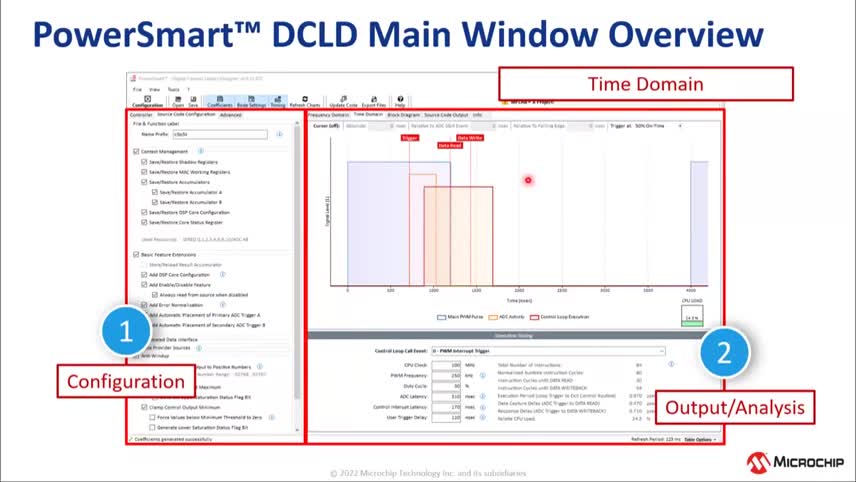
|
TMS320C55x DSP是一種高性能的數字信號處理器,其強大的并行處理能力能夠進一步提高其運算能力。本文介紹了C55xDSP的內核結構以及用戶自定義并行指令時必須遵守如下3條并行處理基本規則,并介紹了6種典型的并行處理應用。利用本文介紹的方法使用并行處理能力將有效提高程序執行效率,同時降低系統功耗。 德州儀器公司(TI)的TMS320C55x(簡稱C55x)DSP內核是在TMS320C54x(簡稱C54x)基礎上開發出來的,并可以兼容C54x的源代碼。C55x的內核電壓降到了1V,功耗降到0.05mW/MIPS,是C54x的1/6。C55x的運行時鐘可以達到 200MHz,是C54x的兩倍,再加上C55x在C54x結構上作了相當大的擴展,程序執行時可以大量采用并行處理,這樣使得C55x的實際運算能力可以達到300MIPS以上。 C55x DSP已越來越多地應用于各種手持便攜終端當中。以下我們將通過詳細介紹C55x的CPU內核結構,討論其并行處理技術的應用。 一 C55x DSP內核結構 C55x DSP是一款采用改良型哈佛結構,高度模塊化的數字信號處理器擁有比普通DSP更為豐富的硬件資源,能夠有效提高運算能力。其內核結構如圖1所示。 圖1 整個處理器內部分為5個大的功能單元:存儲器緩沖單元(M單元)、指令緩沖單元(I單元)、程序控制單元(P單元)、地址生成單元(A單元)和數據計算單元(D 單元),各個功能單元之間通過總線連接。C55x DSP中有1條32位程序數據總線(P總線),1條24位程序地址總線(PA總線),5條16位的數據總線(B、C、D、E、F總線)和5條24位的數據地址總線(BA、CA、DA、EA、FA總線)。這種高度模塊化的多總線結構使得C55x DSP擁有超強的并行處理能力。 M單元主要管理數據區(包括I/O數據區)與中央處理器(CPU)之間的數據傳送,使得高速CPU與外部相對低速的存儲器之間在吞吐量上的瓶頸可以得到一定程度的緩解。 I單元從程序數據總線接收程序代碼,并將其放入指令緩沖隊列(IBQ)中,然后利用指令譯碼器將指令緩沖隊列中的程序代碼進行譯碼,最后再將譯碼后的指令送給P單元、A單元、D單元進行處理。 圖2 P單元主要是通過判斷是否滿足條件執行指令的條件來控制程序地址的產生,達到控制程序流程的目的。程序控制單元中還含有程序控制寄存器、循環控制寄存器、中斷寄存器和狀態寄存器等硬件寄存器。通過循環控制寄存器的設置,可以直接控制程序中的循環次數等,而不必像在普通DSP中一樣在外部對循環條件進行判斷,從而可以有效提高運行效率。 A單元的功能是產生讀寫數據空間的地址。地址生成單元由數據地址產生電路(DAGEN)、16位的算術邏輯單元(ALU)和一組寄存器構成。C55x DSP地址產生與其他功能模塊分開,保證不會因為地址產生的原因使得單條指令需要在多個時鐘周期內完成,提高了DSP的運行效率。A單元中的寄存器包括數據頁寄存器、輔助寄存器、堆棧指針寄存器、循環尋址寄存器和臨時寄存器等。 D單元是C55x DSP中主要的數據執行部件,完成大部分數據的算術運算工作。它由移位器、40位ALU、兩個17位的乘累加器(MAC)和若干寄存器構成。數據計算單元的兩個乘累加器能夠并行使用,可以有效提高DSP運行效率。D單元中的寄存器包括累加器和兩個用于維特比譯碼的專用指令寄存器。 二 并行處理基本準則 如圖1所示C55x DSP內核結構可知,整個處理器的地址及數據運算由P單元、A單元和D單元完成。這三個單元相對獨立,各自通過總線與數據區及程序區相連。這種相互獨立的模塊化結構,在硬件特性上確保這三個單元在同一時鐘周期內能夠進行并行處理,完成各自不同的運算操作。 在C55x DSP指令集中有一些固定搭配的并行執行指令(主要是利用D單元雙MAC結構的并行指令),這些被固定使用的并行指令之間使用“::”符號連接。除了這些固有的并行指令外,用戶也可以根據CPU結構特征自行定義并行指令,并行的兩條指令之間需使用“||”符號連接,以區分指令集中的并行指令。 用戶自定義并行指令時,必須遵守如下3條并行處理基本規則: 規則1: 保證不產生硬件沖突,包括操作數、寄存器、總線及各運算模塊的沖突。在對C55x DSP的所有操作中,對P、A、D三個單元進行操作的指令類型有14類,這14類操作指令之間有很大一部分可以相互并行運行。經過我們對C55x DSP硬件電路結構的分析,在只考慮硬件模塊沖突的情況下,我們得出如圖2所示的C55xDSP并行處理能力分析圖。圖中將14類操作指令組成了一個14 ×14的矩陣,列出了每一類指令與其自身及其他13類指令并行執行的能力。圖中畫有(符號的空格代表不能并行執行,相反沒有任何符號的空格代表可以并行執行。 在考慮并行處理的硬件沖突時,還需要考慮總線資源的沖突。總線資源的沖突通常發生在數據總線和常量總線,C55x DSP中含有5條數據總線和2條常量總線,各條總線與各運算模塊的連接如圖3所示。 數據總線中,C、D總線是讀數據總線,通過這兩條總線進行數據讀取;E、F總線是寫數據總線,通過這兩條總線進行數據寫操作;另外還有一條特殊的B總線,這條總線可以進行讀或寫操作,但是它只能被CDP寄存器使用,而其它輔助寄存器無法使用B總線。 兩條常量總線分別是KA、KD總線。KA常量總線用于產生地址數據。P單元的KA常量總線負責產生程序地址,例如跳轉指令B #RouTIne2中,常量#Routine2就是通過KA常量總線被送到P單元的。A單元的KA常量總線負責產生數據存儲區地址,例如在指令 Mov*SP(#7),Brc0中,偏移量#7就是通過KA常量總線被送到A單元的。KD總線用于傳送參與運算的常量數據,例如指令ADD #123,AC0中,常量123就是通過KD總線傳送的。 規則2:受指令緩沖隊列(IBQ)的限制,并行語句的總長度不能超過6個字節。 I單元中的譯碼器只能將IBQ中的1~6個字節的程序進行譯碼。如果一條并行語句的長度超過6個字節,則需要在兩個時鐘周期內對其進行兩次譯碼。因此必須將兩條并行語句的總長度限制在6個字節。 規則3:當需要尋址兩個及以上數據存儲區數據時,必須使用雙重AR間接尋址方式。 圖3 采用雙重AR間接尋址方式,可以通過使用2個不同的輔助寄存器(AR0~AR7)同時訪問數據存儲區中兩個不同的數據。在這種尋址方式下,我們可以通過兩條不同的數據總線,在同一時鐘周期內尋址兩個不同數據,并將其輸入不同的運算模塊進行計算。 三 常用并行處理應用 在編程實現過程中,對每一個并行處理都進行仔細分析將能達到事半功倍的效果。下面是我們總結出的幾種典型并行處理應用: 1. D單元雙MAC結構的并行處理 在C55x DSP的D單元中采用了雙MAC的結構,其結構如圖4所示。這里有3條數據總線(B、C、D數據總線)與兩個MAC模塊相連。在同一時鐘周期里,可以同時通過3條數據總線將三個不同地址的數據傳入兩個MAC模塊中進行并行計算。 通常情況下,兩個MAC模塊的運算總共需要4個數據,而這里的總線數卻只有3條,所以在并行使用雙MAC結構時,兩個MAC模塊必須共用一組數據,而另外兩組數據分別分配給兩個MAC模塊。這使得雙MAC結構的并行應用受到一定的限制。 C55x的雙MAC結構比較典型的應用如不同數據的相同算法處理和同一數據的不同算法處理。下面是對不同數據進行相同FIR濾波的實例: MAC *AR0+,*CDP+,AC0 ::MAC *AR1+,*CDP+,AC1 其中AR0和AR1寄存器分別指向輸入的兩組數據,CDP寄存器指向FIR濾波器的抽頭系數。C55x DSP的指令集中還含有其它與雙MAC模塊并行處理的專用指令,在此就不再仔細分析。 2. 存儲區數據裝載指令與存儲指令的并行 A單元、P單元和D單元均可以對存儲器中數據實現裝載及存儲。數據的裝載與存儲使用的是不同總線,不會發生硬件沖突,易于實現并行處理。以下是在D單元內實現兩個數據裝載與存儲的實例: MOV AC0,*AR1 ||MOV *AR2,AC1 此例是在D單元內對AC0進行存儲并裝載數據到AC1。程序執行時,將數據通過D總線讀入AC1寄存器,同時將AC0數據通過E總線寫入存儲器,這樣就避免了硬件沖突,滿足并行規則1。兩條指令總長度為4字節,小于IBQ6個字節的限制,滿足了并行規則2。兩條指令均采用雙重間接尋址,滿足了并行規則3。通過上機調試,這條并行指令確實能夠正確編譯并執行。 3. A單元中ALU運算與D單元中ALU、MAC和移位運算的并行 下面我們以一個實例來進行說明: ADD T0,AR1 ||MOV HI(AC0<<#18),*AR2 圖3 這是一個A單元ALU模塊與D單元移位操作模塊的并行處理實例。它在A單元完成16位加法運算,并將結果存放于AR1,同時在D單元完成對寄存器AC0的移位存儲操作。這兩條指令之間不存在硬件沖突,滿足并行規則1。兩條指令總共長度為5個字節,小于IBQ6個字節的限制,滿足了并行規則 2。這里只使用了一個儲器中的數據,不需要滿足并行規則3的規定。通過上機調試,這條并行指令能夠正確編譯并執行。 4. 累加器的移位、飽和及存儲操作與D單元ALU或MAC的并行處理 下面我們以一個實例來進行說明: MOV HI(AC0<<#18),*AR2 ||ADD AC0,AC1 這是一個D單元移位操作模塊與D單元ALU模塊的并行處理實例。它在移位操作模塊中完成寄存器AC0的移位,然后將移位后的值通過E總線存儲到存儲器中,同時在ALU模塊中完成寄存器AC0與AC1的加法運算,然后將結果存放于AC1。這兩條指令不存在硬件沖突,滿足并行規則1。兩條指令總長度為5個字節,小于IBQ6字節的限制,滿足并行規則2。這里只需使用一個存儲器中的數據,不需滿足并行規則3。通過上機調試,這條并行指令能夠正確編譯并執行。 5. 程序控制操作與運算操作的并行 P單元程序控制模塊與其他的算術運算模塊相對較獨立,不易發生硬件沖突,便于進行并行處理。下面是一個程序控制指令與算術運算指令的并行: ADD *AR2,AC0 ||RPTBLOCAL JUMP1 這是一個D單元ALU模塊與P單元程序控制模塊的并行實例。它在D單元ALU中將D總線送來的數據與AC0相加并存入AC0,同時完成程序循環控制。程序執行中不存在硬件模塊和總線的沖突,滿足并行規則1;兩條指令總長度為5字節,滿足并行規則2;此例只使用一個存儲器中的數據,不需要滿足并行規則3。通過上機調試,這條并行指令能夠正確編譯并執行。 6. 使用常量對存儲器進行初始化 D單元擁有兩條寫總線(E、F總線),在通常情況下我們只使用了其中的一條寫總線造成資源浪費。假如我們需要對某塊數據存儲區清零,通常的做法如下: RPT #9 MOV #0,*AR1+ 這段程序對存儲區數據逐一清零,每次只使用了D單元的E總線,總共需要10個時鐘周期才能完成。在這種情況下,如果我們充分利用E、F總線,將有效地降低這段程序的運算量。具體實現如下: MOV #0,AC0 ||RPT #4 MOV AC0,DBL(*AR1+) 這段程序與上一段的最大不同點在于,一個時鐘周期內通過E、F總線將兩個初始數據同時傳送到指定的數據區,同時初始化兩個字的存儲空間。這段程序只需要5個時鐘周期就可以完成10個字的初始化,比普通做法節約一半的運算量,提高了使用效率。 |