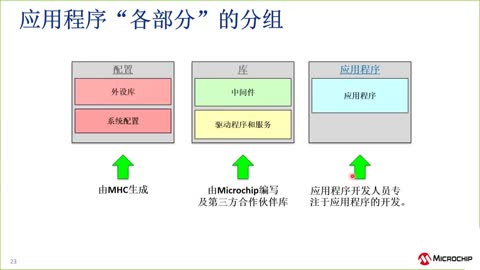
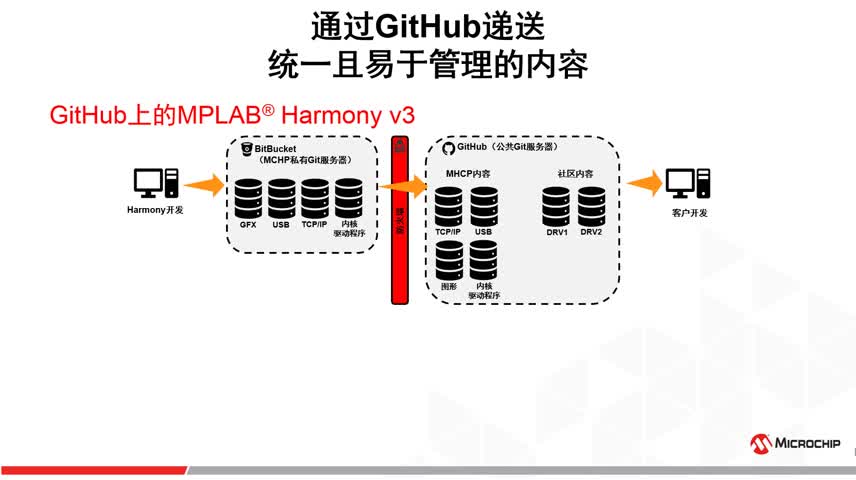
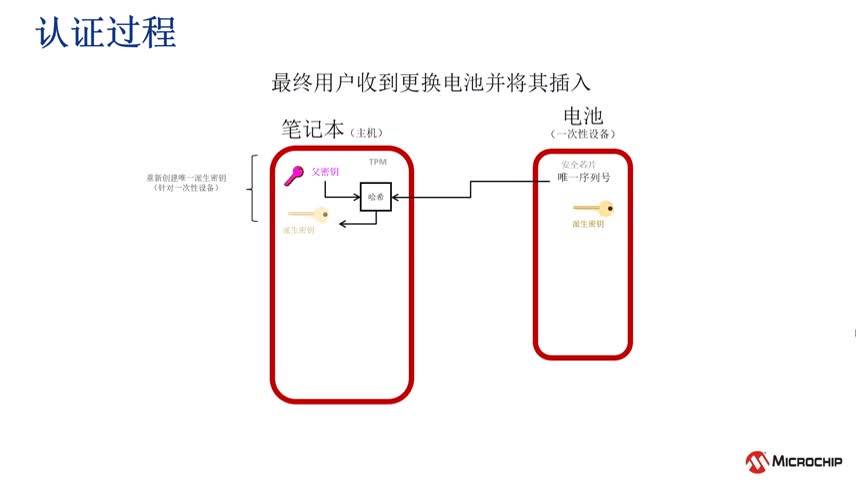
|
引言 流水線技術(shù)通過(guò)多個(gè)功能部件并行工作來(lái)縮短程序執(zhí)行時(shí)間,提高處理器核的效率和吞吐率,從而成為微處理器設(shè)計(jì)中最為重要的技術(shù)之一。ARM7處理器核使用了典型三級(jí)流水線的馮·諾伊曼結(jié)構(gòu),ARM9系列則采用了基于五級(jí)流水線的哈佛結(jié)構(gòu)。通過(guò)增加流水線級(jí)數(shù)簡(jiǎn)化了流水線各級(jí)的邏輯,進(jìn)一步提高了處理器的性能。 ARM7的三級(jí)流水線在執(zhí)行單元完成了大量的工作,包括與操作數(shù)相關(guān)的寄存器和存儲(chǔ)器讀寫(xiě)操作、ALU操作以及相關(guān)器件之間的數(shù)據(jù)傳輸。執(zhí)行單元的工作往往占用多個(gè)時(shí)鐘周期,從而成為系統(tǒng)性能的瓶頸。ARM9采用了更為高效的五級(jí)流水線設(shè)計(jì),增加了2個(gè)功能部件分別訪問(wèn)存儲(chǔ)器并寫(xiě)回結(jié)果,且將讀寄存器的操作轉(zhuǎn)移到譯碼部件上,使流水線各部件在功能上更平衡;同時(shí)其哈佛架構(gòu)避免了數(shù)據(jù)訪問(wèn)和取指的總線沖突。 然而不論是三級(jí)流水線還是五級(jí)流水線,當(dāng)出現(xiàn)多周期指令、跳轉(zhuǎn)分支指令和中斷發(fā)生的時(shí)候,流水線都會(huì)發(fā)生阻塞,而且相鄰指令之間也可能因?yàn)榧拇嫫鳑_突導(dǎo)致流水線阻塞,降低流水線的效率。本文在對(duì)流水線原理及運(yùn)行情況詳細(xì)分析的基礎(chǔ)上,研究通過(guò)調(diào)整指令執(zhí)行序列來(lái)提高流水線運(yùn)行性能的方法。 1 ARM7/ARM9流水線技術(shù) 1.1 ARM7流水線技術(shù) ARM7系列處理器中每條指令分取指、譯碼、執(zhí)行三個(gè)階段,分別在不同的功能部件上依次獨(dú)立完成。取指部件完成從存儲(chǔ)器裝載一條指令,通過(guò)譯碼部件產(chǎn)生下一周期數(shù)據(jù)路徑需要的控制信號(hào),完成寄存器的解碼,再送到執(zhí)行單元完成寄存器的讀取、ALU運(yùn)算及運(yùn)算結(jié)果的寫(xiě)回,需要訪問(wèn)存儲(chǔ)器的指令完成存儲(chǔ)器的訪問(wèn)。流水線上雖然一條指令仍需3個(gè)時(shí)鐘周期來(lái)完成,但通過(guò)多個(gè)部件并行,使得處理器的吞吐率約為每個(gè)周期一條指令,提高了流式指令的處理速度,從而可達(dá)到 O.9 MIPS/MHz的指令執(zhí)行速度。 在三級(jí)流水線下,通過(guò)R15訪問(wèn)PC(程序計(jì)數(shù)器)時(shí)會(huì)出現(xiàn)取指位置和執(zhí)行位置不同的現(xiàn)象。這須結(jié)合流水線的執(zhí)行情況考慮,取指部件根據(jù)PC取指,取指完成后PC+4送到PC,并把取到的指令傳遞給譯碼部件,然后取指部件根據(jù)新的PC取指。因?yàn)槊織l指令4字節(jié),故PC值等于當(dāng)前程序執(zhí)行位置+8。 1.2 ARM9流水線技術(shù) ARM9系列處理器的流水線分為取指、譯碼、執(zhí)行、訪存、回寫(xiě)。取指部件完成從指令存儲(chǔ)器取指;譯碼部件讀取寄存器操作數(shù),與三級(jí)流水線中不占有數(shù)據(jù)路徑區(qū)別很大;執(zhí)行部件產(chǎn)生ALU運(yùn)算結(jié)果或產(chǎn)生存儲(chǔ)器地址(對(duì)于存儲(chǔ)器訪問(wèn)指令來(lái)講);訪存部件訪問(wèn)數(shù)據(jù)存儲(chǔ)器;回寫(xiě)部件完成執(zhí)行結(jié)果寫(xiě)回寄存器。把三級(jí)流水線中的執(zhí)行單元進(jìn)一步細(xì)化,減少了在每個(gè)時(shí)鐘周期內(nèi)必須完成的工作量,進(jìn)而允許使用較高的時(shí)鐘頻率,且具有分開(kāi)的指令和數(shù)據(jù)存儲(chǔ)器,減少了沖突的發(fā)生,每條指令的平均周期數(shù)明顯減少。 2 三級(jí)流水線運(yùn)行情況分析 三級(jí)流水線在處理簡(jiǎn)單的寄存器操作指令時(shí),吞吐率為平均每個(gè)時(shí)鐘周期一條指令;但是在存在存儲(chǔ)器訪問(wèn)指令、跳轉(zhuǎn)指令的情況下會(huì)出現(xiàn)流水線阻斷情況,導(dǎo)致流水線的性能下降。圖1給出了流水線的最佳運(yùn)行情況,圖中的MOV、ADD、SUB指令為單周期指令。從T1開(kāi)始,用3個(gè)時(shí)鐘周期執(zhí)行了3條指令,指令平均周期數(shù)(CPI)等于1個(gè)時(shí)鐘周期。 
流水線中阻斷現(xiàn)象也十分普遍,下面就各種阻斷情況下的流水線性能進(jìn)行詳細(xì)分析。 2.1 帶有存儲(chǔ)器訪問(wèn)指令的流水線 對(duì)存儲(chǔ)器的訪問(wèn)指令LDR就是非單周期指令,如圖2所示。這類(lèi)指令在執(zhí)行階段,首先要進(jìn)行存儲(chǔ)器的地址計(jì)算,占用控制信號(hào)線,而譯碼的過(guò)程同樣需要占用控制信號(hào)線,所以下一條指令(第一個(gè)SUB)的譯碼被阻斷,并且由于LDR訪問(wèn)存儲(chǔ)器和回寫(xiě)寄存器的過(guò)程中需要繼續(xù)占用執(zhí)行單元,所以下一條(第一個(gè) SUB)的執(zhí)行也被阻斷。由于采用馮·諾伊曼體系結(jié)構(gòu),不能夠同時(shí)訪問(wèn)數(shù)據(jù)存儲(chǔ)器和指令存儲(chǔ)器,當(dāng)LDR處于訪存周期的過(guò)程中時(shí),MOV指令的取指被阻斷。因此處理器用8個(gè)時(shí)鐘周期執(zhí)行了6條指令,指令平均周期數(shù)(CPI)=1.3個(gè)時(shí)鐘周期。
2.2 帶有分支指令的流水線 當(dāng)指令序列中含有具有分支功能的指令(如BL等)時(shí),流水線也會(huì)被阻斷,如圖3所示。分支指令在執(zhí)行時(shí),其后第1條指令被譯碼,其后第2條指令進(jìn)行取指,但是這兩步操作的指令并不被執(zhí)行。因?yàn)榉种е噶顖?zhí)行完畢后,程序應(yīng)該轉(zhuǎn)到跳轉(zhuǎn)的目標(biāo)地址處執(zhí)行,因此在流水線上需要丟棄這兩條指令,同時(shí)程序計(jì)數(shù)器就會(huì)轉(zhuǎn)移到新的位置接著進(jìn)行取指、譯碼和執(zhí)行。此外還有一些特殊的轉(zhuǎn)移指令需要在跳轉(zhuǎn)完成的同時(shí)進(jìn)行寫(xiě)鏈接寄存器、程序計(jì)數(shù)寄存器,如BL執(zhí)行過(guò)程中包括兩個(gè)附加操作——寫(xiě)鏈接寄存器和調(diào)整程序指針。這兩個(gè)操作仍然占用執(zhí)行單元,這時(shí)處于譯碼和取指的流水線被阻斷了。 2.3 中斷流水線 處理器中斷的發(fā)生具有不確定性,與當(dāng)前所執(zhí)行的指令沒(méi)有任何關(guān)系。在中斷發(fā)生時(shí),處理器總是會(huì)執(zhí)行完當(dāng)前正被執(zhí)行的指令,然后去響應(yīng)中斷。如圖 4所示,在Ox90000處的指令A(yù)DD執(zhí)行期間IRQ中斷發(fā)生,這時(shí)要等待ADD指令執(zhí)行完畢,IRQ才獲得執(zhí)行單元,處理器開(kāi)始處理IRQ中斷,保存程序返回地址并調(diào)整程序指針指向Oxl8內(nèi)存單元。在Oxl8處有IRO中斷向量(也就是跳向IRQ中斷服務(wù)的指令),接下來(lái)執(zhí)行跳轉(zhuǎn)指令轉(zhuǎn)向中斷服務(wù)程序,流水線又被阻斷,執(zhí)行0x18處指令的過(guò)程同帶有分支指令的流水線。
3 五級(jí)流水線技術(shù) 五級(jí)流水線技術(shù)在多種RISC處理器中被廣泛使用,被認(rèn)為是經(jīng)典的處理器設(shè)計(jì)方式。五級(jí)流水線中的存儲(chǔ)器訪問(wèn)部件(訪存)和寄存器回寫(xiě)部件,解決了三級(jí)流水線中存儲(chǔ)器訪問(wèn)指令在指令執(zhí)行階段的延遲問(wèn)題。圖5為五級(jí)流水線的運(yùn)行情況(五級(jí)流水線也存在阻斷)。
3.1 五級(jí)流水線互鎖分析 五級(jí)流水線只存在一種互鎖,即寄存器沖突。讀寄存器是在譯碼階段,寫(xiě)寄存器是在回寫(xiě)階段。如果當(dāng)前指令(A)的目的操作數(shù)寄存器和下一條指令(B)的源操作數(shù)寄存器一致,B指令就需要等A回寫(xiě)之后才能譯碼。這就是五級(jí)流水線中的寄存器沖突。如圖6所示,LDR指令寫(xiě)R9是在回寫(xiě)階段,而MOV中需要用到的 R9正是LDR在回寫(xiě)階段將會(huì)重新寫(xiě)入的寄存器值,MOV譯碼需要等待,直到LDR指令的寄存器回寫(xiě)操作完成。(注:現(xiàn)在處理器設(shè)計(jì)中,可以通過(guò)寄存器旁路技術(shù)對(duì)流水線進(jìn)行優(yōu)化,解決流水線的寄存器沖突問(wèn)題。)
雖然流水線互鎖會(huì)增加代碼執(zhí)行時(shí)間,但是為初期的設(shè)計(jì)者提供了巨大的方便,可以不必考慮使用的寄存器會(huì)不會(huì)造成沖突;而且編譯器以及匯編程序員可以通過(guò)重新設(shè)計(jì)代碼的順序或者其他方法來(lái)減少互鎖的數(shù)量。另外分支指令和中斷的發(fā)生仍然會(huì)阻斷五級(jí)流水線。 3.2 五級(jí)流水線優(yōu)化 采用重新設(shè)計(jì)代碼順序在很多情況下可以很好地減少流水線的阻塞,使流水線的運(yùn)行流暢。下面詳細(xì)分析代碼優(yōu)化對(duì)流水線的優(yōu)化和效率的提高。 要實(shí)現(xiàn)把內(nèi)存地址0x1000和Ox2000處的數(shù)據(jù)分別拷貝到0x8000和0x9000處。 Oxl000處的內(nèi)容:1,2,3,4,5,6,7,8,9,10 Ox2000處的內(nèi)容:H,e,l,l,o,W,o,r,l,d 實(shí)現(xiàn)第一個(gè)拷貝過(guò)程的程序代碼及指令的執(zhí)行時(shí)空?qǐng)D如圖7所示。
全部拷貝過(guò)程由兩個(gè)結(jié)構(gòu)相同的循環(huán)各自獨(dú)立完成,分別實(shí)現(xiàn)兩塊數(shù)據(jù)的拷貝,并且兩個(gè)拷貝過(guò)程極為類(lèi)似,分析其中一個(gè)即可。 T1~T3是3個(gè)單獨(dú)的時(shí)鐘周期;T4~T11是一個(gè)循環(huán),在時(shí)空?qǐng)D中描述了第一次循環(huán)的執(zhí)行情況。在T12的時(shí)候?qū)慙R的同時(shí),開(kāi)始對(duì)循環(huán)的第一條語(yǔ)句進(jìn)行取指,所以總的流水線周期數(shù)為3+10×10+2×9=121。整個(gè)拷貝過(guò)程需要121×2+2=244個(gè)時(shí)鐘周期完成。 考慮到通過(guò)減少流水線的沖突可以提高流水線的執(zhí)行效率,而流水線的沖突主要來(lái)自寄存器沖突和分支指令,因此對(duì)代碼作如下兩方面調(diào)整: ①將兩個(gè)循環(huán)合并成一個(gè)循環(huán)能夠充分減少循環(huán)跳轉(zhuǎn)的次數(shù),減少跳轉(zhuǎn)帶來(lái)的流水線停滯; ②調(diào)整代碼的順序,將帶有與臨近指令不相關(guān)的寄存器插到帶有相關(guān)寄存器的指令之間,能夠充分地避免寄存器沖突導(dǎo)致的流水線阻塞。 對(duì)代碼調(diào)整和流水線的時(shí)空?qǐng)D如圖8所示。
調(diào)整之后,T1~T5是5個(gè)單獨(dú)的時(shí)鐘周期,T6~T13是一個(gè)循環(huán),同樣在T14的時(shí)候BNE指令在寫(xiě)LR的同時(shí),循環(huán)的第一條指令開(kāi)始取指,所以總的指令周期數(shù)為5+10×10+2×9+2=125。 通過(guò)兩段代碼的比較可看出:調(diào)整之前整個(gè)拷貝過(guò)程總共使用了244個(gè)時(shí)鐘周期,調(diào)整了循環(huán)內(nèi)指令的順序后,總共使用了125個(gè)時(shí)鐘周期就完成了同樣的工作,時(shí)鐘周期減少了119個(gè),縮短了119/244=48.8%,效率提升十分明顯。 代碼優(yōu)化前后執(zhí)行周期數(shù)對(duì)比的情況如表1所列。
因此流水線的優(yōu)化問(wèn)題主要應(yīng)從兩方面考慮: ①通過(guò)合并循環(huán)等方式減少分支指令的個(gè)數(shù),從而減少流水線的浪費(fèi); ②通過(guò)交換指令的順序,避免寄存器沖突造成的流水線停滯。 4 結(jié)論 流水線技術(shù)提高了處理器的并行性,與串行CPU相比大大提高了處理器性能。通過(guò)調(diào)節(jié)指令序列的方法又能夠有效地避免流水線沖突的發(fā)生,從而提高了流水線的執(zhí)行效率。因此如何采用智能算法進(jìn)行指令序列的自動(dòng)調(diào)節(jié)以提高流水線的效率和進(jìn)一步提高處理器的并行性將是以后研究的主要方向。 參考文獻(xiàn) 1. John L Hennessy.David A Patterson 計(jì)算機(jī)系統(tǒng)結(jié)構(gòu):量化研究方法 2004 2. ARM Architecture Reference Manual 2005 3. Samsung Electronics Co Ltd S3C44B0X 32-bit RISC Microprocessor User's Manuel 2003 4. Samsung Electronics Co Ltd S3C2410X 32-bit RISC Microprocessor User's Manuel 2003 5. 田澤 嵌入式系統(tǒng)開(kāi)發(fā)與應(yīng)用 2005 6. Wayne W 嵌入式計(jì)算機(jī)系統(tǒng)設(shè)計(jì)原理 2002 作者:大連理工大學(xué) 邱鐵 西方 遲宗正 來(lái)源:單片機(jī)與嵌入式系統(tǒng)應(yīng)用 2009 (3) |