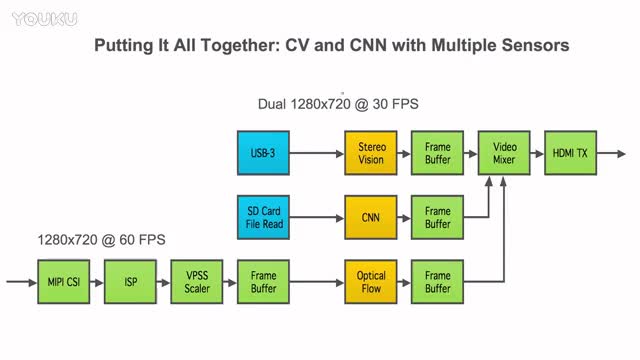
|
���� ����C(j��)���W(xu��)��(x��)���^(gu��)���漰����(g��)���E�������x��һ��(g��)ģ�ͣ�ᘌ�(du��)�ض��΄�(w��)����Ӗ(x��n)�����Üy(c��)ԇ��(sh��)��(j��)�M(j��n)���(y��n)�C��Ȼ��ԓģ�Ͳ���(sh��)�Hϵ�y(t��ng)�в��M(j��n)�бO(ji��n)�ء��ڱ����У��҂���ӑՓ�@Щ���E����ÿ��(g��)���E����v���(l��i)��B�C(j��)���W(xu��)��(x��)�� �C(j��)���W(xu��)��(x��)��ָ�ڛ](m��i)�����_ָ�����r���܉�?q��)W��(x��)�ͼ��Ը��M(j��n)��ϵ�y(t��ng)���@Щϵ�y(t��ng)�Ĕ�(sh��)��(j��)�ЌW(xu��)��(x��)�����ڈ�(zh��)���ض����΄�(w��)���ܡ���ijЩ��r�£��W(xu��)��(x��)�����߸����w���f(shu��)��Ӗ(x��n)���������ܱO(ji��n)���ķ�ʽ���M(j��n)�У���(d��ng)ݔ�������_�r(sh��)��(du��)ģ�ͼ����{(di��o)����ʹ���������_��ݔ������������r�£��t��(sh��)�Пo(w��)�O(ji��n)���W(xu��)��(x��)����ϵ�y(t��ng)ؓ(f��)؟(z��)���픵(sh��)��(j��)��(l��i)�l(f��)�F(xi��n)��ǰδ֪��ģʽ�������(sh��)�C(j��)���W(xu��)��(x��)ģ�Ͷ�����ѭ�@�ɷN��ʽ���O(ji��n)���W(xu��)��(x��)�c�o(w��)�O(ji��n)���W(xu��)��(x��)���� �F(xi��n)�ڣ��҂������о���ģ�͡��ĺ��x��Ȼ��̽����(sh��)��(j��)��γɞ�C(j��)���W(xu��)��(x��)��ȼ�ϡ� �C(j��)���W(xu��)��(x��)ģ�� ģ���ǙC(j��)���W(xu��)��(x��)��Q�����ij�������ģ�Ͷ��x�ܘ�(g��u)���ܘ�(g��u)��(j��ng)�^(gu��)Ӗ(x��n)��׃�ɮa(ch��n)Ʒ��(sh��)�F(xi��n)�����ԣ��҂����Dz���ģ�ͣ����Dz���(j��ng)�^(gu��)��(sh��)��(j��)Ӗ(x��n)����ģ�͵Č�(sh��)�F(xi��n)������һ��(ji��)���и���Ԕ��(x��)�Ľ�B����ģ�� + ��(sh��)��(j��) + Ӗ(x��n)��=�C(j��)���W(xu��)��(x��)��Q�����Č�(sh��)�����D1���� 
�D1���ęC(j��)���W(xu��)��(x��)ģ�͵���Q���������DԴ�����ߣ� �C(j��)���W(xu��)��(x��)��Q��������һ��(g��)ϵ�y(t��ng)����������ݔ�룬�ھW(w��ng)�j(lu��)�Ј�(zh��)�в�ͬ��͵�Ӌ(j��)�㣬Ȼ���ṩݔ����ݔ���ݔ�����픵(sh��)ֵ�͔�(sh��)��(j��)���@��ζ������ijЩ��r�£���Ҫ�D(zhu��n)�g�����磬���ı���(sh��)��(j��)ݔ����ȌW(xu��)��(x��)�W(w��ng)�j(lu��)��Ҫ�����~���a�ɔ�(sh��)����ʽ�����]������ʹ�õĆ��~�Ķ����ԣ�ԓ��(sh��)����ʽͨ���Ǹ߾S������ͬ�ӣ�ݔ��������Ҫ�Ĕ�(sh��)����ʽ�D(zhu��n)�g���ı���ʽ�� �C(j��)���W(xu��)��(x��)ģ���ж�N��ͣ�����(j��ng)�W(w��ng)�j(lu��)ģ�͡�ؐ�~˹ (Bayesian) ģ�͡��ؚwģ�͡����ģ�͵ȡ����x���ģ���ǻ������ֽ�Q�Ć�(w��n)�}�� ��(du��)����(j��ng)�W(w��ng)�j(lu��)��(l��i)�f(shu��)��ģ�͏Ĝ\���ӾW(w��ng)�j(lu��)�������(j��ng)�W(w��ng)�j(lu��)������S�����������(j��ng)�W(w��ng)�j(lu��)߀���������ػ���(j��ng)Ԫ��̎���Ԫ���������(j��ng)�W(w��ng)�j(lu��)߀��һϵ�л���Ŀ��(bi��o)��(y��ng)�õĿ���ģ�͡����磺 ������đ�(y��ng)�Â�(c��)�����R(sh��)�e�D���еČ�(du��)����ô���e��(j��ng)�W(w��ng)�j(lu��) (CNN) ���������ģ�͡�CNN�ѱ���(y��ng)����Ƥ�w���z�y(c��)��Ч����(y��u)��Ƥ�w���t(y��)����ƽ��ˮƽ�� ������đ�(y��ng)���漰�A(y��)�y(c��)�����ɏ�(f��)�s���У�������Z(y��)�Ծ��ӣ�����ô�f�w��(j��ng)�W(w��ng)�j(lu��) (RNN) ���L(zh��ng)����ӛ���W(w��ng)�j(lu��) (LSTM) ������ģ�͡�LSTMҲ�ѽ�(j��ng)��(y��ng)�õ�����Z(y��)�ԵęC(j��)�����g�С� ������đ�(y��ng)���漰������Z(y��)�������D���(n��i)�ݣ�����ʹ��CNN��LSTM�ĽM�ϣ��D��ݔ��CNN��CNN��ݔ������LSTM��ݔ�룬���߰l(f��)���~�R���У��� ������đ�(y��ng)���漰���ɬF(xi��n)��(sh��)�D�����L(f��ng)������Ę������ô���Ɍ�(du��)���W(w��ng)�j(lu��) (GAN) �Ǯ�(d��ng)ǰ�����M(j��n)��ģ�͡� �@Щģ�ʹ����ˮ�(d��ng)���õIJ��������(j��ng)�W(w��ng)�j(lu��)�ܘ�(g��u)�������(j��ng)�W(w��ng)�j(lu��)���ܚgӭ����?y��n)��������Խ��ܷǽY(ji��)��(g��u)����(sh��)��(j��)����D��ҕ�l�����l��Ϣ���W(w��ng)�j(lu��)�еĸ��Ә�(g��u)��һ��(g��)�����ӴνY(ji��)��(g��u)��ʹ�����܉�?q��)��dz��?f��)�s����Ϣ�M(j��n)�з�������(j��ng)�W(w��ng)�j(lu��)�ѽ�(j��ng)���S����(w��n)�}�I(l��ng)��չʾ�����M(j��n)�����ܡ������������C(j��)���W(xu��)��(x��)ģ��һ�ӣ������Ĝ�(zh��n)�_����ه�ڔ�(sh��)��(j��)������(l��i)�҂���̽ӑһ���@��(g��)���档 ��(sh��)��(j��)��Ӗ(x��n)�� �o(w��)Փ���\(y��n)���У�߀����ͨ�^(gu��)ģ��Ӗ(x��n)����(g��u)���C(j��)���W(xu��)��(x��)��Q�������^(gu��)���У���(sh��)��(j��)�Ԟ��(q��)��(d��ng)�C(j��)���W(xu��)��(x��)��ȼ�ϡ���(du��)�������(j��ng)�W(w��ng)�j(lu��)��Ӗ(x��n)����(sh��)��(j��)��̽����(sh��)�����|(zh��)��ǰ���µı�Ҫ��(sh��)��(j��)���P(gu��n)��Ҫ�� �����(j��ng)�W(w��ng)�j(lu��)��Ҫ������(sh��)��(j��)�M(j��n)��Ӗ(x��n)��������(j��ng)�(y��n)��(l��i)�f(shu��)���D������ÿ���Ҫ1,000���D�����w���@Ȼȡ�Q��ģ�͵ď�(f��)�s�Ⱥ����e(cu��)�ȡ���(sh��)�H�C(j��)���W(xu��)��(x��)��Q�����е�һЩʾ����������(sh��)��(j��)���и��N��С��һ��(g��)�沿�z�y(c��)���R(sh��)�eϵ�y(t��ng)��Ҫ45�f(w��n)���D��һ��(g��)��(w��n)�������C(j��)������Ҫ����20�f(w��n)��(g��)��(w��n)�}��200�f(w��n)��(g��)ƥ��𰸵�Ӗ(x��n)��������(j��)Ҫ��Q�Ć�(w��n)�}���Еr(sh��)�^С�Ĕ�(sh��)��(j��)��Ҳ���һ��(g��)��з�����Q����������(j��)��(sh��)���ı��_���^�c(di��n)�ĘO�ԣ�ֻ��Ҫ��(sh��)�f(w��n)��(g��)�ӱ��� ��(sh��)��(j��)���|(zh��)���͔�(sh��)��ͬ����Ҫ���b��Ӗ(x��n)����Ҫ��(sh��)��(j��)������ʹ�������e(cu��)�`Ӗ(x��n)����(sh��)��(j��)Ҳ��(hu��)��(d��o)�����Ľ�Q����������(j��)����Ĕ�(sh��)��(j��)��ͣ���(sh��)��(j��)���ܕ�(hu��)��(j��ng)�vһ��(g��)��ϴ�^(gu��)�̡����^(gu��)�̴_����(sh��)��(j��)��һ�¡��](m��i)���؏�(f��)��(sh��)��(j��)�Ҝ�(zh��n)�_���������](m��i)�Пo(w��)Ч��������(sh��)��(j��)�����п���֧�ִ��^(gu��)�̵Ĺ��ߡ��(y��n)�C��(sh��)��(j��)��ƫ��Ҳ����Ҫ���_����(sh��)��(j��)����(hu��)��(d��o)����ƫ��ęC(j��)���W(xu��)��(x��)��Q������ �C(j��)���W(xu��)��(x��)Ӗ(x��n)����(du��)��(sh��)ֵ�͔�(sh��)��(j��)�M(j��n)���\(y��n)�㣬��ˣ�����(j��)���Ľ�Q������������Ҫ�A(y��)̎�����E�����磬�����(sh��)��(j��)������Z(y��)�ԣ����������D(zhu��n)�g�锵(sh��)����ʽ����̎�������Ԍ�(du��)�D���M(j��n)���A(y��)̎���Ա���һ���ԡ����磬���������\(y��n)���⣬ݔ�������(j��ng)�W(w��ng)�j(lu��)�ĈD��߀��Ҫ�{(di��o)����С��ƽ��̎������ȥ������ �C(j��)���W(xu��)��(x��)�����Ć�(w��n)�}֮һ�ǫ@ȡ��(sh��)��(j��)����(l��i)Ӗ(x��n)���C(j��)���W(xu��)��(x��)��Q����������(j��)���ľ��w��(w��n)�}���@��(g��)���������ܷdz�����?y��n)���ܛ](m��i)�ЬF(xi��n)�ɵĔ�(sh��)��(j��)����Ҫ�������O(sh��)���@ȡ�� ���(y��ng)ԓ�ָ(sh��)��(j��)�����քe����Ӗ(x��n)����(sh��)��(j��)�͜y(c��)ԇ��(sh��)��(j��)��Ӗ(x��n)����(sh��)��(j��)����Ӗ(x��n)��ģ�ͣ���Ӗ(x��n)����ɺy(c��)ԇ��(sh��)��(j��)�����(y��n)�C��Q�����Ĝ�(zh��n)�_�ԣ��D2����
�D2���ָ(sh��)��(j��)���քe����Ӗ(x��n)�����(y��n)�C�����DԴ�����ߣ� �й��߁�(l��i)��������@��(g��)�^(gu��)�̣������(sh��)��ܶ����С��ָ���ܣ����ڷָ�Ӗ(x��n)���͜y(c��)ԇ��(sh��)��(j��)���F(xi��n)���҂���(l��i)��һЩ��(ji��n)���C(j��)���W(xu��)��(x��)��Q������(g��u)��Ŀ�ܡ� ��� �F(xi��n)�ڣ�������Ҫ���^�_(k��i)ʼ��(g��u)���C(j��)���W(xu��)��(x��)ģ�͡�������ʹ�ð����@Щģ�ͺ��������ߵĿ�܁�(l��i)��(zh��n)�䔵(sh��)��(j��)���(y��n)�C���Ľ�Q�������@Щ���߀�ṩ���ڲ����Q�����ĭh(hu��n)�����x���Ă�(g��)���ͨ��ȡ�Q��������Ϥ�̶ȣ����ڄ��_(k��i)ʼ�ĕr(sh��)������x��һ��(g��)�m����Ҫʹ�õđ�(y��ng)���cģ�͵Ŀ�ܡ� TensorFlow����õ���ȌW(xu��)��(x��)��ܡ���֧���������е�ģ�ͣ�CNN��RNN��LSTM�ȣ��������S��ʹ��Python��C++�M(j��n)���_(k��i)�l(f��)���ĸ߶˷���(w��)�����Ƅ�(d��ng)�O(sh��)�䣬���ɲ���TensorFlow��Q������������������֣�TensorFlow��һ��(g��)���e(cu��)�����c(di��n)�����н̳̺��S�����ęn�� CAFFE�����һ��(g��)�W(xu��)�g(sh��)�(xi��ng)Ŀ�����ڰl(f��)�����_(k��i)Դ���ѽ�(j��ng)�l(f��)չ�ɞ�һ��(g��)���е���ȌW(xu��)��(x��)��ܡ�CAFFE����C++����(xi��)����Ҳ֧��Pythonģ���_(k��i)�l(f��)��ͬTensorFlowһ�ӣ���Ҳ֧�֏V������ȌW(xu��)��(x��)ģ�͡� PyTorch�Ŀ���С�PyTorch����һ��(g��)�ܺõ��x���������S���Ŀ�����Ϣ��������(g��u)����ͬ��ͽ�Q�����Č�(sh��)�`�̡̳� R�Z(y��)�Ժͭh(hu��n)���ǙC(j��)���W(xu��)��(x��)�͔�(sh��)��(j��)�ƌW(xu��)�����й��ߡ���齻��ʽ���ߣ��Ɏ�������(g��u)����Q������ԭ�ͣ�ͬ�r(sh��)���A�β鿴�Y(ji��)��������Keras��һ��(g��)�_(k��i)Դ����(j��ng)�W(w��ng)�j(lu��)��(k��)�����������ØO�������_(k��i)�l(f��)Ͷ���(l��i)��(g��u)��CNN��RNN�� ģ�͌��� һ��ģ�ͽ�(j��ng)�^(gu��)Ӗ(x��n)�����M���˜�(zh��n)�_��Ҫ���ɲ������a(ch��n)ϵ�y(t��ng)�С����ǵ����@һ������Ҫ���˽�Q�������Դ_�������Ҫ���]��?j��ng)Q������ģ�́�(l��i)���Լ���(du��)�˂���Ӱ푣��@һ�c(di��n)�Ȟ���Ҫ�� ��Щ�C(j��)���W(xu��)��(x��)ģ�������ģ��������⣨���磬�Q�ߘ�(sh��)�����������(j��ng)�W(w��ng)�j(lu��)������ģ�ͱ��J(r��n)���ǡ����䡱���Q�����ɔ�(sh��)���f(w��n)��(g��)�o(w��)����ģ�ͱ�����ጵ�Ӌ(j��)�������ġ���ˣ��^(gu��)ȥһ�ȿ��Խ��ܶ��ڌ��ˣ����ǣ��B�m(x��)��������Ѹ�ٳɞ��@Щ������r�µĘ�(bi��o)�䣬��?y��n)��e(cu��)�`�Dz��ɱ���ġ�һ���l(f��)�F(xi��n)�e(cu��)�`���@Щ��Ϣ���������{(di��o)��ģ�͵Ĕ�(sh��)��(j��)�� ��һ��(g��)���]�ǽ�Q�������������ڡ�ģ�͕�(hu��)˥�ˣ�ݔ�딵(sh��)��(j��)��(hu��)�l(f��)��׃�����Ķ���(d��o)��ģ�����ܵ�׃������ˣ���횽��ܽ�Q�����S���r(sh��)�g�����ƕ�(hu��)׃���������C(j��)���W(xu��)��(x��)��Q��������S����?ch��)������׃��������������׃�?br /> ���Y(ji��) ���˲���C(j��)���W(xu��)��(x��)��Q�������҂���һ��(g��)��(w��n)�}�_(k��i)ʼ��Ȼ�]���ܵĽ�Qģ�͡�����(l��i)�ǫ@ȡ��(sh��)��(j��)����(j��ng)�^(gu��)���_�����ͷָ�Ϳ���ʹ�ÙC(j��)���W(xu��)��(x��)���Ӗ(x��n)�����(y��n)�Cģ�͡��������еĿ�ܶ�����ͬ�ģ������Ը���(j��)����ģ�ͺͽ�(j��ng)�(y��n)��(l��i)�x��͑�(y��ng)�á�Ȼ��ʹ��ԓ��ܲ���C(j��)���W(xu��)��(x��)��Q������ͨ�^(gu��)�m��(d��ng)?sh��)Č��ˣ���Q�����������挍(sh��)������ʹ�Ì�(sh��)�r(sh��)��(sh��)��(j��)�M(j��n)���\(y��n)�㡣 ��(l��i)Դ���Q(m��o)����� ���ߣ�M. Tim Jones |