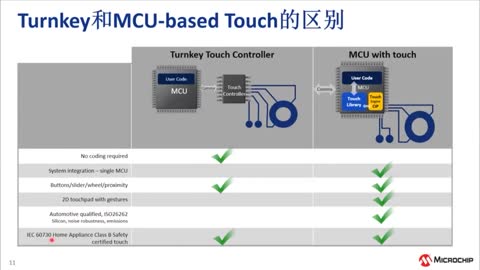
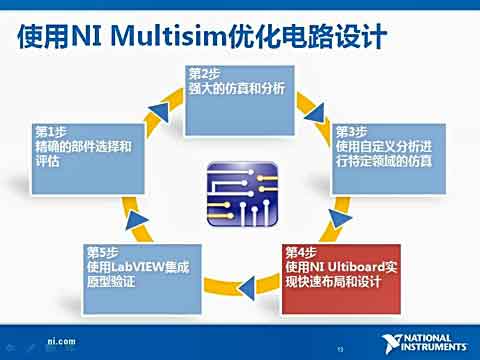
|
現象一:這主頻100M的CPU只能處理70%,換200M主頻的就沒事了 點評:系統的處理能力牽涉到多種多樣的因素,在通信業務中其瓶頸一般都在存儲器上,CPU再快,外部訪問快不起來也是徒勞。 現象二:CPU用大一點的CACHE,就應該快了 點評:CACHE的增大,并不一定就導致系統性能的提高,在某些情況下關閉CACHE反而比使用CACHE還快。原因是搬到CACHE中的數據必須得到多次重復使用才會提高系統效率。所以在通信系統中一般只打開指令CACHE,數據CACHE即使打開也只局限在部分存儲空間,如堆棧部分。同時也要求程序設計要兼顧CACHE的容量及塊大小,這涉及到關鍵代碼循環體的長度及跳轉范圍,如果一個循環剛好比CACHE大那么一點點,又在反復循環的話,那就慘了。 現象三:這么多任務到底是用中斷還是用查詢呢?還是中斷快些吧 點評:中斷的實時性強,但不一定快。如果中斷任務特別多的話,這個沒退出來,后面又接踵而至,一會兒系統就將崩潰了。如果任務數量多但很頻繁的話,CPU的很大精力都用在進出中斷的開銷上,系統效率極為低下,如果改用查詢方式反而可極大提高效率,但查詢有時不能滿足實時性要求,所以最好的辦法是在中斷中查詢,即進一次中斷就把積累的所有任務都處理完再退出。 現象四:存儲器接口的時序都是廠家默認的配置,不用修改的 點評:BSP對存儲器接口設置的默認值都是按最保守的參數設置的,在實際應用中應結合總線工作頻率和等待周期等參數進行合理調配。有時把頻率降低反而可提高效率,如RAM的存取周期是70ns,總線頻率為40M時,設3個周期的存取時間,即75ns即可;若總線頻率為50M時,必須設為4個周期,實際存取時間卻放慢到了80ns。 現象五:一個CPU處理不過來,就用兩個分布處理,處理能力可提高一倍 點評:對于搬磚頭來說,兩個人應該比一個人的效率高一倍;對于作畫來說,多一個人只能幫倒忙。使用幾個CPU需對業務有較多的了解后才能確定,盡量減少兩個CPU間協調的代價,使1+1盡可能接近2,千萬別小于1。 現象六:這個CPU帶有DMA模塊,用它來搬數據肯定快 點評:真正的DMA是由硬件搶占總線后同時啟動兩端設備,在一個周期內這邊讀,那邊些。但很多嵌入CPU內的DMA只是模擬而已,啟動每一次DMA之前要做不少準備工作(設起始地址和長度等),在傳輸時往往是先讀到芯片內暫存,然后再寫出去,即搬一次數據需兩個時鐘周期,比軟件來搬要快一些(不需要取指令,沒有循環跳轉等額外工作),但如果一次只搬幾個字節,還要做一堆準備工作,一般還涉及函數調用,效率并不高。所以這種DMA只對大數據塊才適用。 相關文章: 硬件設計雞毛蒜皮之一 硬件設計雞毛蒜皮之二 硬件設計雞毛蒜皮之四 硬件設計雞毛蒜皮之五 |