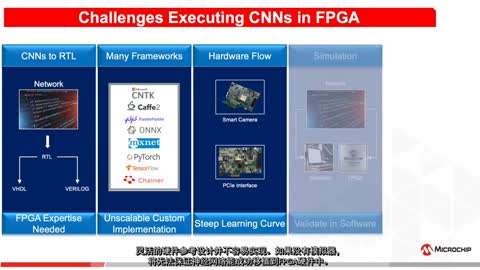
|
12LP+��ˇ���ƾ��w�ܣ�IP������(j��ng)�W(w��ng)�j(lu��) ���ߣ�Linley Gwennap��2020��7��27�գ� ��Nvidia�@�ӵ�оƬ���^����ؓ(f��)��(d��n)����7nm���g(sh��)��������(chu��ng)��˾������Ҏ(gu��)ģ�^С�Ĺ�˾�s��?y��n)�?f��)�s���O(sh��)Ӌ(j��)Ҏ(gu��)�t�߰�����Ƭ�ɱ����������ѡ��������@Щ���Ǟ����ھ��w���ٶȺͳɱ�����ȡ���m�ȵĸ��ơ���о������12LP+���g(sh��)�ṩ��һ�l���;����ͨ�^�pС늉������Ǿ��w�ܳߴ�������ġ���о߀�_�l(f��)�ˌ��Tᘌ�AI���ٶ���(y��u)��������SRAM�ͳ˷��ۼ�(MAC)�·����Y(ji��)���ǣ�����AI�\(y��n)��Ĺ������ɜp��75%��Groq��Tenstorrent�ȿ͑��ѽ�(j��ng)���ó���12LP���g(sh��)�@���˘I(y��)���I(l��ng)�ȵĽY(ji��)������������12LP+��ˇ����Įa(ch��n)Ʒ���ڽ�����Щ�r(sh��)����Ƭ�� ���ˌ�(sh��)�F(xi��n)�@Щ�Y(ji��)������о(GF)��ȡ�����w����������AI�\(y��n)�㣬�e���������e��(j��ng)�W(w��ng)�j(lu��)(CNN)���˹���ؓ(f��)�d�dz���هMAC�\(y��n)�㣬����о�l(f��)�F(xi��n)���ֹ��Č�(sh��)�H�����ڏı���SRAM�xȡ��(sh��)��(j��)�������ݔ?sh��)�MAC��Ԫ�ϡ��µ�SRAM�O(sh��)Ӌ(j��)�����CNN��������(j��ng)���L���L��(sh��)��(j��)�����đ�(y��ng)�õĹ��ġ��µ�MACᘌ������(sh��)AI���������^С��(sh��)��(j��)��ͺ��^�͕r(sh��)��ٶȶ��O(sh��)Ӌ(j��)���@Ҳ�����ڹ�(ji��)ʡ���ġ�SRAM��Ԫ�еijɌ����w�ܽ�(j��ng)�^�����O(sh��)Ӌ(j��)�����ƥ��ȣ�ʹ늉����Խ��ͣ��Ķ��pС�����늉�ԣ���� ��о�ڷŗ�7nm����С�������g(sh��)��Ӌ(j��)��֮���D(zhu��n)���x�����@�l��·����ע��FD-SOI��SiGe������������g(sh��)����ҊMPR 8/13/18������о��(zh��n)�ԡ�����12LP+��AI�����Ŭ������������(zh��n)�Ե���һ���C���@�N�����ă�(y��u)����ijЩ����Ҫ��7nm�����ɱ����͡���ǰ���@�Ҿ��A�S��ע������AMD��˾�ĸ�����CPU�����S��AMD����I(y��)��(w��)�D(zhu��n)�����_(t��i)�e늣���ӆ��đ�(zh��n)���ю�����о�������¿͑��� ��AI���O(sh��)Ӌ(j��) �ڵ��͵ĸ�����CPU�У�����SRAMÿ�����ṩһ��(g��)�����ľ����У�Ȼ��CPUͨ�^��·��(f��)����(mux)�x��������֡����磬ʹ��256λ�����е�64λCPU��Ҫһ��(g��)4:1��·��(f��)��������D1(a)��ʾ�����@�N��r�£���ʹCPUÿ��(g��)���ڃHʹ��64λ��SRAM����е�����256λ������Ҳ��(hu��)��ÿ���L���r(sh��)��늡��@�N�������̶ȵpС��SRAM���t���Ķ��п���������r(sh��)��ٶȻ�p����ˮ������(sh��)�����@���߶���Ӱ�CPU���ܵ��P(gu��n)�I���ء� 
�D1. ��оAI���ô惦(ch��)����ͨ��������̶ȵpС���S�C(j��)��ȡ�����t�������i������(hu��)�������t������(hu��)��������ȡ�Ĺ��ġ� AI������ͨ���Ա�PC̎�����͵ĕr(sh��)��ٶ��\(y��n)�У����O(sh��)Ӌ(j��)�����P(gu��n)�����������������t�����⣬CPUͨ�������S�C(j��)��ȡģʽ����CNN�a(ch��n)���Ąt�����惦(ch��)����ȡ����̎���������������Д�(sh��)��Ӌ(j��)��(sh��)��ǧӋ(j��)��Ԫ�ء����˸��õ�֧���@Щ�O(sh��)Ӌ(j��)����о��SRAM��кͶ�·��(f��)����֮�g������һ��(g��)�i��������D1(b)��ʾ���@������(hu��)�o�xȡ·������һ��(g��)���ڣ�CPU�O(sh��)Ӌ(j��)���^����(hu��)�����@�N������������AI�����������˿��^�ĺ�̎�� ���ȣ��i��������·��(f��)�����c��н���Ķ��pСλ�������ϵ�������M(j��n)������ÿ��SRAM��ȡ�Ĺ��ġ�������ĺ�̎�ǣ����x����֮��������256λݔ����λ���i�����С�����S����x�����L����һ��(g��)�f���惦(ch��)����ַ����ô���ԏ��i�������xȡԓֵ���������o���(q��)��(d��ng)��С����ڏĺ��L��һϵ������ַ�xȡ��(sh��)��(j��)�ij����O(sh��)Ӌ(j��)ֻ����25%�ĕr(sh��)�g��(n��i)��SRAM��й�늡����]��������·��(f��)�������i����������(g��)�·����о��Ӌ(j��)�������ژ�(bi��o)��(zh��n)���g��SRAM��CNN����ؓ(f��)�d�Ĺ��Ŀɽ���53%�����ڕr(sh��)��s��׃�Ì��ɣ��µ�SRAMҲ�sС��25%�� �M��MAC��Ԫ�Ĺ��ăHռ�����ĵ�һС���֣�������e����ռ��оƬ��e����֡����O(sh��)Ӌ(j��)����һ��(g��)16x16λ�˷������c�߶�CPU�����64λ�O(sh��)Ӌ(j��)��ͬ������(sh��)��4��Booth�˷�������һ��(g��)48λ�ӷ��������M(j��n)�и߾����ۼӡ�����CNN�����г�Ҋ��8λ����(sh��)(INT8)��(sh��)��(j��)�����Ԍ�MAC��Ԫ��֞�ÿ��(g��)���ڮa(ch��n)���ɂ�(g��)8x8�˷������M(j��n)��24λ�ۼӡ���о��Ŀ��(bi��o)�����l�ʞ�1.0GHz�������O(sh��)Ӌ(j��)������Ժ��������ĺ�оƬ��e���ԜpС���µ�MAC��Ԫ��֮ǰ��12LP��ԪС12%������ͬ늉��¶���1.0GHz�\(y��n)�Еr(sh��)������Ĺ��Ĝp��25%��
�D2. 12LP+���ܺĽ������ڵ��͵��}��(d��ng)MAC����У��µ�SRAM��MAC�O(sh��)Ӌ(j��)ʹ�����ı�֮ǰ��12LP���g(sh��)����������֮һ����������늉���ʹ�����Ľ���������֮һ������(sh��)��(j��)��Դ����о�� ��pС늉��������Ĵ������� �����M(j��n)һ�������ģ���о�ڹ���늉��Ϻ��¹��oՓʲô��(ji��)�c(di��n)��һ��(g��)��Ҫ����(zh��n)�ǹ������w�ܵ�����ƫ��ŘO�͜ϵ����Π��Ȼ��s�ϵ�С����ܕ�(hu��)��׃���w�ܵĹ�����(sh��)����������Ƅ�(d��ng)ͨ�^�������������ą���(sh��)����������(sh��)��(hu��)���ֵ늉����Ķ��Q�����w�ܺΕr(sh��)�ГQ��B(t��i)�����ڽo����ˇ�����A�S��(hu��)������늉��O(sh��)�õ����ߣ��Դ_��оƬ�ϵ����о��w�ܶ��ܿɿ����_�P(gu��n)��������횳��^�����r�µ��ֵ늉��� ���ˑ�(y��ng)���@һ����(zh��n)��12LP+�������p������(sh��)���w�ܡ��˼��g(sh��)ԭ���Ǟ�7nm��ˇ���_�l(f��)�ģ���о������ֲ����12nm��(ji��)�c(di��n)�С����O(sh��)Ӌ(j��)�Բ�ͬ��ʽ���sNMOS��PMOS���w�ܣ��Ա���õ�ƽ���书����(sh��)���@�N������(hu��)ʹ�ɱ��������ӣ�������������ԣ��������1.0GHz��Ŀ��(bi��o)�l�ʣ�SRAM�Ĺ���늉���12LP��0.7V����12LP+��0.55V��12LP߉�Ę�(bi��o)�Q늉���0.8V��Ƿ�(q��)늉���0.7V������12LP+�У���Ҳ���Բ���0.55V���������ڹ����c늉���ƽ���ɱ���������@Щ׃������ʹ���Ĝp�롣 SRAM����Ҫ�ĺ�����������Ը�о��ע���_�l(f��)�͉��惦(ch��)����Ԫ���yԇоƬ�@ʾ����ʹ��0.45V늉��£�����LVSRAM�������Գ��^95%���@��ζ���O(sh��)Ӌ(j��)��0.55V늉��¾��г����ԣ������ʹ߉�������棬��оί��Arm������֪�R(sh��)�a(ch��n)��(qu��n)(physical-IP)С�M��12LP+��ˇ��(chu��ng)����һ��(g��)�����ĵ͉���(bi��o)��(zh��n)��Ԫ�졣ԓ�춨��9�����У��͑����������혋(g��u)��������AI��������SRAM��MAC��Ԫ����0.55V늉������� �¼��g(sh��)�Ŀ���(ji��)�Ч���dz��@������о��MAC��Ԫ���}��(d��ng)��У��@��CNN���ٵij�Ҋ���ã��Ĺ����M(j��n)���������������xȡ��(qu��n)�غͼ���D2���@ʾ��SRAM���ģ�����(sh��)��(j��)�Ƅ�(d��ng)ͨ�^�}��(d��ng)��У���ݔ����Ȼ���(zh��)��Ӌ(j��)��(MAC)�������ڻ����O(sh��)Ӌ(j��)���µ�MAC��Ԫ���i��SRAMʹ���ܺĜp��������֮һ���ϣ�����ݔ�ܺı��ֲ�׃����0.55V늉�������(hu��)�a(ch��n)��һ��(g��)ȫ��Ĵ���ʹԓ�O(sh��)Ӌ(j��)�Ŀ���(ji��)����_(d��)��68%�� �c����һ�ӣ���оͨ�^�V��������Ԫ���죨������(sh��)�֡�ģ�M�͟oԴ��������֧��12LP+��ˇ����о�ṩEDA���ߣ���Cadence��Synopsys�������Spiceģ�͡��O(sh��)Ӌ(j��)Ҏ(gu��)�t�z�������r(sh��)��ģ���Լ����ֲ������ܡ�����������ʣ���о�ṩ�������Ŀ��������O(sh��)Ӌ(j��)(DFM)���̡���о��ᘌ�12LP+����(y��u)����12LP����IP�������惦(ch��)����I/O�ӿڡ�����Arm�ĵ͉���(bi��o)��(zh��n)��Ԫ���⣬Rambus��Synopsys�ȵ�����IP����(y��ng)��Ҳ֧��12LP+�� ����AI�I(l��ng)�ȹ�˾ �@�(xi��ng)�¼��g(sh��)�����ڸ�о�ɹ���12LP��ˇ���A(ch��)�ϣ����ИI(y��)�I(l��ng)�ȵ�AI�a(ch��n)Ʒ�ṩ���������磬��ȳ���(chu��ng)��˾Groq�_�l(f��)��һ�N�µļܘ�(g��u)���������ټ���(sh��)�ق�(g��)���܆�Ԫ�چ�(g��)�����е���(j��ng)�W(w��ng)�j(lu��)��������O(sh��)Ӌ(j��)����220MB��SRAM��200,000���ϵ�MAC��Ԫ����ҊMPR 1/6/20����Groq����(d��ng)��(j��ng)�W(w��ng)�j(lu��)������Groq����12LPʹ��˴����O(sh��)Ӌ(j��)�Ĺ��ı�����300W���A(y��)��֮��(n��i)��ԓоƬ��1.0GHz�ij�ʼ�ٶȣ���INT8��(sh��)��(j��)��(sh��)�F(xi��n)��ÿ��820�f�|���\(y��n)��(TOPS)�ķ�ֵ�����������^�����������Ѱl(f��)���ļ������� ���ô����(chu��ng)��˾TenstorrentҲ�ӿ��������ٶȣ������x����һ��(g��)��ͬ���O(sh��)Ӌ(j��)Ŀ��(bi��o)��������늵�PCIe���Ĺ�����ֵ��75W�����һ��оƬ����120��(g��)��(d��)���ĺ��ģ�ÿ��(g��)���İ���1MB��SRAM�ʹ�s500��(g��)MAC��Ԫ���@�N������Ȼ��Ҫ������SRAM��MAC��Ԫ��ԓоƬ��1.3GHz�ij�ʼ�ٶȿ��ṩ368 TOPS����ҊMPR 4/13/20����Tenstorrent����AI���ܡ�����12LP���g(sh��)����Tenstorrent��(sh��)�F(xi��n)��ÿ��4.9 TOPS�����ܣ��@һЧ���ڔ�(sh��)��(j��)���Įa(ch��n)Ʒ���b�b�I(l��ng)�ȣ���D3��ʾ�� ���@��(g��)�Ј���ռ�������~��Nvidia����l(f��)���˻�������Ampere�ܘ�(g��u)��A100��������Ampere�������S����(chu��ng)�����ԣ���ֵ������ߵ�624 TOPS�����^�˳�Groq֮��������Ѱl(f��)��оƬ��Ȼ�����M�ܲ���7nm��ˇ����A100����Ҫ400W TDP����֮ǰ��12nm�a(ch��n)Ʒ߀��33%�������m��(y��ng)�����A(y��)������ӣ�Nvidia���ò����͕r(sh��)��ٶȣ�������12nm�a(ch��n)Ʒ����������оƬ��15%�ĺ��ġ��@��һ�N�������IJ��ԣ�������ζ��оƬ���Ĵ����ڷ��湦�ģ���ҊMPR 6/8/20����Nvidia A100�Q��AI���ܡ�������ˣ��mȻA100�ľ��w���^С������ÿ�����܇�(y��n)�������Groq��TenstorrentоƬ�� �c��о��12nm��ˇ��ȣ��_(t��i)�e�7nm��ˇ��һ��(g��)��(y��u)�c(di��n)�Ǿ��w���ܶ�����һ����ʹ��Nvidia�Ɍ����^500�|��(g��)���w�ܷ��b��A100�С����ˎ����͑����@���渂������о֧�ָ��NСоƬ��������о�ڶ�оƬ���b��������S���Ľ�(j��ng)�(y��n)���������иߎ����惦(ch��)��(HBM)��2.5D���н���O(sh��)Ӌ(j��)��ᘌ�3DоƬ�ѯB����о���_�l(f��)����Ͼ��A�I��(HWB)���g(sh��)����ʹ���g����5.76�Ĺ�ͨ��(TSV)�������ܶ�������·���D�����ڵ��ܶȻ��B���͑������ڱ��˵��ЙC(j��)�r���Ϙ�(g��u)��СоƬ���ã������AMD��Rome̎�������@ЩСоƬ�����е��κ�һ�N�����ڲ��w�Ƶ�7nm��ˇ����r��(sh��)�F(xi��n)�ܸߵľ��w�ܔ�(sh��)���� �r(ji��)���؛��r ��о��12LP+���g(sh��)�ѿ������O(sh��)Ӌ(j��)����(d��ng)���҂��A(y��)Ӌ(j��)���a(ch��n)����2021���°����_ʼ�����P(gu��n)�����ھ���Ϣ��Ո?ji��n)L��tinyurl.com/yxam2z7l�� ��(y��u)��7nm �_(t��i)�e��Q����������10nm��(ji��)�c(di��n)����7nm���g(sh��)��ʹ�r(sh��)��ٶ���߶��_(d��)20%�����Ľ��Ͷ��_(d��)40%����ҊMPR 5/20/19����EUV��ˇ��(sh��)�F(xi��n)���a(ch��n)���������ǣ��@Щ�����r�µĔ�(sh��)�ֶ��ٶ����w�ܵ�ؓ(f��)�d���p����(f��)�s��̎�����O(sh��)Ӌ(j��)ͨ�������ڽ�����ݶ����Ǿ��w���ٶȣ����ֻ�ܫ@��������̎��һ�����١���ǰ������Nvidia��7nm A100����12nm��ǰ���a(ch��n)ƷҪ��������ͨ��˾��7nm̎����Snapdragon 855�����CPU�ٶȃH��Snapdragon 845�����2%���_(t��i)�e��A(y��)��5nm�����挢С��7nm����?y��n)�����ʹ��EUV��(hu��)����ÿƬ���A����Ƭ�ijɱ��� ��о��12LP+�ṩ��һ�l���·�����c�_(t��i)�e늵�7nm��ȣ����Ĵ�����ͣ��ɱ��t�]�����ӡ����Ľ�����Ҫ?d��)w�����µ��p������(sh��)���w�ܣ���֧��0.55V늉��x�(xi��ng)���_(t��i)�e늵�7nm���g(sh��)�ṩ����VT (ULVT)���w�ܣ��乤��늉���͞�0.6V���_(t��i)�e��L���ԁ�����(w��)�������֙C(j��)�͑�����ע�ڵ͉�����������о����(c��)����PC��ֱ������Űl(f��)����׃����������@������M(j��n)���ںܴ�̶����Ǐ��a(b��)��ࡣ
�D3. �߶�AI���������^���cNvidia���®a(ch��n)ƷA100��ȣ�Groq TSP�����ܸ���(qi��ng)�ţ���ÿ���f�|���\(y��n)���TOPS�������������ąs���͡�Tenstorrent������Ŀ��(bi��o)�^�ͣ�����Ч��ÿ��TOPS����A100������������(sh��)��(j��)��Դ������(y��ng)�̣� 12LP+��������(y��u)�݁�����ԓ���g(sh��)����AI�O(sh��)Ӌ(j��)��SRAM��MAC��Ԫ���@�N������ӳ�˾��A�S�IJ�����_(t��i)�e늱�횷���(w��)�ڏV���Ŀ͑�������о���Ԍ�ע���ض������d����ؓ(f��)�d��AI�Ј�����ɹ��S�T����?y��n)���̫��Ĺ�˾���e�dz���(chu��ng)��˾�����_�l(f��)CNN�����������Ϳ͑�ͨ����(hu��)�����O(sh��)Ӌ(j��)�����MAC��Ԫ������о���O(sh��)Ӌ(j��)����ϣ�����_�l(f��)�ɱ�������Ͷ���ע�ڪ�(d��)�ؼܘ�(g��u)�ij���(chu��ng)��˾�����á� ���L�چ��}�ǣ��ڛ]��7nm����С�������g(sh��)��·���D����r�£���о�ָܷ��������_(t��i)�e늵�5nm���g(sh��)�������a(ch��n)�У��͑��ѽ�(j��ng)����(d��ng)δ����(ji��)�c(di��n)���O(sh��)Ӌ(j��)���@Щ���M(j��n)�Ĺ�ˇʹ�O(sh��)Ӌ(j��)���܉�?q��)������?ch��)����MAC��Ԫ����оƬ�С��Ј����~���Ĵ���˾���^�m(x��)���@�l·����ȥ������AI�Ј���С��˾�t��(hu��)�l(f��)�F(xi��n)12LP+����(sh��)�ݣ����ҿ���ʹ��СоƬ����(j��ng)��(j��)��Ч����߾��w�ܔ�(sh��)����Groq��Tenstorrentͨ�^��о��12LP���g(sh��)��(sh��)�F(xi��n)���I(l��ng)�ȵ�AI���ܣ�12LP+�е�AI����(qi��ng)���܌�ʹ�¼��g(sh��)����Խ�� |