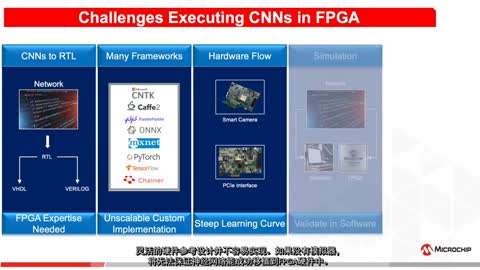
|
在本周的2020 VLSI技術與電路研討會上,英特爾將針對分布于核心、邊緣和端點上的日益增長的數據所引起的計算轉型,介紹一系列研究成果和技術觀點。首席技術官Mike Mayberry將發表題為“未來計算:數據轉型如何重塑VLSI”的主題演講,重點強調從以硬件/程序為中心的計算過渡到以數據/信息為中心的計算的重要性。 “在分布式邊緣、網絡和云基礎架構上有巨量數據流動,這就要求在數據生成的位置附近進行高能效和強大的處理,但這種處理往往會受到帶寬、內存和電源資源的制約。英特爾研究院在VLSI研討會上重點展示了提高計算效率的幾種新方法,這些方法顯示出多種應用領域的廣闊前景,包括機器人、增強現實、機器視覺和視頻分析。這一系列研究的重點在于解決數據移動和計算方面的障礙,這些障礙代表了未來最大的數據挑戰。” - Vivek K. De,英特爾fellow,英特爾研究院電路技術研究總監 將要展示的內容:此次研討會上將介紹一些英特爾的研究論文,探討在未來邊緣-網絡-云系統中如何能夠實現更高的智能水平和更高能效,以支持日益增長的眾多邊緣應用。研究論文中涉及的部分主題(研究的完整列表請見本新聞稿文末)包括: 利用光線投射硬件加速器,提高邊緣機器人三維場景重建的效率和精度 論文:在邊緣機器人和增強現實應用中,通過10納米CMOS的光線投射加速器進行高效3D場景重建 重要意義:包括邊緣機器人和增強現實在內的某些應用,需要通過從光線投射操作產生的大量數據中精確、快速并且高能效地對復雜的3D場景進行重建,以實現實時密集的同步定位和映射(SLAM)。在本研究論文中,英特爾重點介紹了一款新型光線投射硬件加速器,可以利用新技術來保持場景重建的準確性,同時實現卓越的高能效性能。這些創新方法包括三維像素重疊搜索和硬件輔助近似計算三維像素等技術,降低了對本地內存的需求,此外還提升了電源效率,以適應未來的邊緣機器人和增強現實應用。 利用事件驅動可視化數據處理單元(EPU),降低基于深度學習的視頻流分析的功耗 論文:一個0.05pJ/像素 70fps FHD 1Meps事件驅動的可視數據處理單元 重要意義:基于實時深度學習的可視數據分析主要用于安全和安保等領域,要求在多個視頻流中能夠快速檢測對象,因而需要較長計算時間和高內存帶寬。通常會對這些攝像頭中的輸入幀進行下采樣,以便讓負載降到最低,這樣就降低了圖像精度。在本項研究中,英特爾演示了一個事件驅動的視覺數據處理單元(EPU)在結合新穎的算法之后,可指示深度學習加速器僅使用基于運動的“目標區域”來處理視覺輸入。這種新型方法緩解了邊緣視覺分析中的密集計算和高內存要求。 擴展本地內存帶寬,以滿足人工智能、機器學習和深度學習應用的需求 論文:針對內存帶寬有限的工作負載而設計的2倍帶寬突發6T-SRAM 重要意義:很多AI芯片,尤其是那些用于自然語言處理的芯片(如語音助理),日益受到本地內存的制約。為應對內存方面的挑戰,需要提供倍頻或增加內存插槽的數量,但其代價是功耗和面積效率變低,對于面積受限的邊緣設備而言尤其如此。通過這項研究,英特爾展示了如何使用6T-SRAM陣列,以便在突發模式下根據需要提供2倍的讀取帶寬,其能效比倍頻高51%,面積效率則比倍增內存插槽數量高30%。 全數字二進制神經網絡加速器 論文:采用10納米FinFET CMOS的617TOPS/W全數字二進制神經網絡加速器 重要意義:在功率和資源受限的邊緣設備中,某些應用可接受低精度輸出,因而可將模擬二進制神經網絡(BNN)作為更高精度神經網絡的替代品。后者的計算要求更高,并且有密集內存要求。然而,模擬BNN的預測精度較低,因為它們對過程變化和噪聲的容忍度較低。通過本研究,英特爾演示了全數字BNN的使用,它具有類似于模擬輸入內存技術能效,同時又為先進過程節點提供了更好的魯棒性和可擴展性。 2020 VLSI研討會上介紹的其他英特爾研究包括以下論文: • 未來計算:數據轉型如何重塑VLSI • 適用于10納米CMOS的高性能圖形/AI處理器的低時鐘功率數字標準單元IP • 適用于具有動態電流控制的多核SoC的一種自主重構功率輸出網絡(RPDN) • 3D單片異構集成實現300毫米硅片(111)上的GaN和Si晶體管 • 低擺幅和列多路復用位線技術,適用于10納米FinFET CMOS的低Vmin、耐噪聲、高密度1R1W 8T位單元SRAM • 一種具有動態電流控制的雙軌混合模擬/數字LDO,適用于可調諧的高PSRR和高效率 • 一種435MHz、600Kops/J的抗側信道攻擊加密處理器,適用于14納米CMOS的安全RSA-4K公鑰加密 • 一種14納米CMOS的0.26% BER 10^28抗建模挑戰響應PUF,具有穩定性感知對抗挑戰選擇(Stability-Aware Adversarial Challenge Selection)功能 • 一種6000倍時域/頻域泄漏抑制的抗SCA AES引擎,采用非線性數字低漏失調節器,并與14納米CMOS的運算對策級聯 • 帶重金屬雙層底部電極的SOT-MRAM CMOS兼容工藝集成和帶STT輔助的10ns無場SOT轉換 • 采用柵極調制自折疊寫入輔助的10納米SRAM設計,能夠以微乎其微的電能開支使VMIN減少175毫伏 |