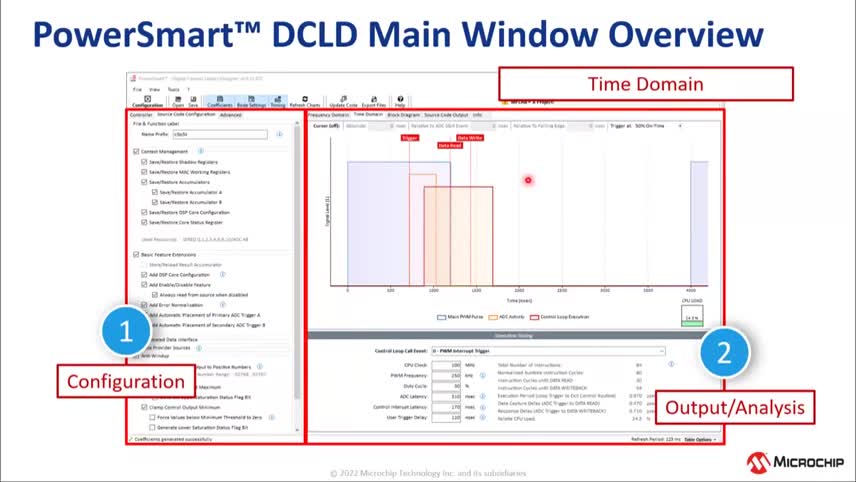
|
隨著在數字信號處理(DSP)算法和芯片處理能力以及通信網絡結構優化等方面的不斷發展,現代化通信已經迅速普及。音頻會議是眾多通信系統的必備功能。有多個用戶參與的音頻會議,最簡單的模式可以使用令牌控制下的互斥模式,使只有擁有發言權的那個與會者才可以講話。在這種模式下,每個與會者某一時刻只能聽到一路音頻信號,這種“半雙工”模式對于音頻會議是不方便和不實際的。 真正的電話會議應當仿真多個與會者在一個會議室進行對話的情形。但是由于與會終端在物理上并不在一起,而每個終端只有一套音頻輸出設備(功放+音箱),要同時傳送給每個終端的音頻流也只能使用一路信道。為使每個終端同時接收多個與會者的聲音,必須采取多路音頻合成方案。電話會議的特點是會場使用麥克風和揚聲器,這種方式很容易造成回波干擾和嘯叫。一般會議信號處理算法主要關注的也是這個方面,通常采用回波抵消的方法。但是這種方式對于會議信號的處理并不是最完善和有效的。經過研究,采用有無聲檢測、歸一化定標、自適應回波抵消算法合成技術則能夠很真實地實現會議仿真效果。 1 會議信號合成實現方案 1.1 會議信號合成的合理性和必要性 音頻流不象典型的視頻流一樣在空間/時間域占有惟一的位置,在同一時間和位置的信號元素疊加是沒有任何意義的。但人耳可以感知在同一空間/時間播放多個音頻流。這就是會議信號合成的合理性和必要性。通過會議信號的合成,將多路音頻流的輸入經過處理后,提供一個單輸出信道輸出合成音頻。 1.2 會議信號合成的關鍵因素 當多個音頻源在一個空間播放時,人耳聽到的聲波是各個聲源聲波的線性疊加,這正是模擬音頻信號合成的基礎。該事實表明數字化后的語音進行合成也應當使用線性疊加的方式。假設有n路輸入音頻流進行混音,Xi(t)是t時刻的第i路輸入語音的線性樣本,則t時刻的混音值為: m(t)=ΣXi(t),i=0,1,…,n-1 語音信號是連續的、時間要求嚴格的一種流媒體信號,它在時域上具有短時平穩的特征。對語音信號進行處理的一個基本概念就是對語音信號進行采樣,得到的語音樣本以緩沖區為單位進行處理,即對語音樣本分幀。語音處理的很多概念都是基于語音幀的,比如有聲/無聲、能量、自相關等。語音幀的長度一般采用10~20ms。 數字音頻的重要參數是采樣率,各路輸入音頻流合成的前提應當是使用相同的采樣率。 隨著需要合成的語音信道數量的增加,在不采取任何附加預防措施的情況下,一些并非會議有效信號(如聲反饋和噪音)就會累積起來導致質量劣化,讓人無法接受。特別是由本地擴聲系統產生的電聲反饋引起的回音造成了再生混響,其結果嚴重地影響了語音的清晰度。更為致命的是當聲反饋非常嚴重時會產生自激,使整個通信系統無法正常工作。所以必須對每個終端的輸入音頻進行有無聲檢測和聲反饋抑制處理。 語音合成時應注意求和樣本的動態范圍,這引出了歸一化定標問題。數字音頻波形理論定義,定標就是檢查某個選定的幀,找到振幅峰值,并由此調整被選幀整體的音量,以便使允許的振幅值最大,且不會溢出。語音合成是對數字波形進行的一種編輯,尤其需要解決歸一化定標問題。 2 會議信號合成關鍵技術研究 2.1 自適應回波抵消算法 數字回波抵消器的理論基礎是自適應濾波器技術。隨著DSP的快速發展,數字回波抵消器已能很好地在DSP上加以應用。在電話會議中產生回波的最主要原因是遠端會議信號經本地揚聲系統在室內產生的聲場回饋至傳聲器引起回音造成的再生混響。 回波抵消器必須精確地估計回波路徑特性并快速適應其變化,根據電話會議的特點,使用干涉抵消模型是最佳的方式。該模型是一個具有二個輸入端的自適應濾波器,如圖1所示。它將本地的傳聲器輸出作為原始信號,而將本地揚聲器的輸入作為參考信號。經過自適應回波抵消處理后,能有效地抑制本地傳聲器的輸出經室內聲場饋至傳聲器的電聲反饋(回音),從而實現自適應聲反饋(回音)的抵消。 回波抵消的核心就是自適應濾波器算法。常見的算法包括SDA算法和LMS算法。由于SDA算法中梯度的計算涉及到矩陣,并不適合實際應用。通過其派生的LMS算法簡單實用,計算效率高。TI公司的DSP芯片TMS320C54X有專門的LMS指令用于加速自適應濾波算法。在實際應用中,還可以在LMS算法的基礎上得到修改濾波器系數的算法: 詳細的自適應回波抵消算法計算步驟如下: (1) 采樣值; (2) 根據前一次的計算值和濾波器系數修改算法,進行系數調整; (3) 計算遠端估計能量; δ2[k] = (1-α) δ2[k-1] +α X2[k] (4) 進行FIR濾波計算, 求得濾波器的輸出y(n)和誤差信號e(n); (5) 數據輸出; (6) 跳轉到第一步。 2.2 有無聲能量檢測 在ITU-T協議中有無聲檢測即語音激活檢測(Voice Activity Detection)。在多點音頻會議中,有無聲檢測使得在某一時段實際語音合成的終端數目大大少于與會者數目,降低了合成運算量,減輕了處理芯片的負擔。同時也是麥克風自適應增益控制AGC的基礎。 在數字語音信號中,有無聲檢測是通過信號能量、過零率參數的組合,與預置的能量門限值進行比較得出。基于短時平均能量的計算是利用一個固定寬度的滑動窗口,每輸入一個最新樣本,計算該樣本之前的窗口覆蓋的所有樣本的能量平均值,將其與一個能量門限值比較來判斷該新樣本是靜音還是有聲。 如上所述,以幀為單位對數字語音進行檢測,如果某一幀內有任何一個樣本是有聲,則該幀就是有聲。將窗口以幀為單位滑動,而不是以樣本為單位,直接憑每幀的最后一個樣本是有無聲來確定該幀是有聲幀或無聲幀,這種簡化的判斷方式大大節省了運算量。對判斷的結果而言并無影響。 使用自適應變化的能量門限可以更加準確地對有無聲加以判斷。可以通過樣本短時能量的一階線性低通濾波得到背景噪聲能量。而自適應能量門限值則保持與短時背景噪聲能量一個靜音檢測的靈敏度常量比值So。長時間連續講話會升高背景噪聲的估計值,這就相應地提高了靜音檢測能量門限,有可能造成緊接著發生的低幅值的講話當作靜音而未被檢測到。所以當檢測到話音時可以通過改變低通濾波器的截止頻率來重新估計噪聲能量。 在過濾靜音的同時應當注意如何保留短時能量相對較低的微弱音頻信號,如摩擦音和輔音。這些微弱信號的存在保證了語音語義的完整性,所以在短時平均能量判斷之外還應該結合過零率的判別保留這些微弱音頻信號。采用余音生成器的方式可以實現微弱音頻信號的保留,即余音生成器將緊跟在一個語音串后的頭幾幀。所謂無聲的幀仍然應該被當作是有聲,從而避免低電平語音被抑制掉。ITU-T G.723.1A對余音生成器算法作了較詳細的設計,在此不做詳細描述。 2.3 歸一化定標處理 多路語音信號合成時采用線性疊加,必須解決的問題是如何防止疊加產生溢出而導致失真。如果采樣樣本是16bit,而求和緩沖區也是16bit,那兩路音頻流就容易使求和區溢出。即使提供了高精度的求和緩沖區,使得在求和過程中不會溢出,但是這不能保證求和結果的幅值適合輸出硬件器件的要求范圍(DA器件范圍通常是16bit)。 簡單的方法是對超出范圍的值箝位。更好的方法是對求和結果分幀進行歸一化定標,具體就是:對某個求和語音幀中的所有樣本分析,若樣本S的值超過了器件所能表示的最大范圍,那么S之后的所有樣本均乘以一個衰減因子f。其中f是能夠使S滿足輸出器件范圍的最大值,顯然,f的絕對值小于1。這樣在箝位后的一段時間內,語音樣本之間的大小是相對不變的。 在實驗中選用了通用的16bit定點DSP芯片TMS320C549進行實時仿真來完成多路音頻流的合成。各路線性樣本相加過程中,求和的值是不會溢出的,因為樣本是16bit,而累加器是32bit。但和值很容易超過輸出硬件設備允許的范圍(16bit)。 在歸一化定標處理中,初始化時衰減因子f為1,每次開始處理一個新的樣本緩沖區時,任何一個樣本S超過了范圍,將S箝位,并且求得S與允許范圍值的比值f,在時序上位于S之后的樣本都除以f。但是為了避免語音不必要的衰減,而箝位操作有讓f越來越小的趨勢,因此需要有讓f變大的地方,這發生在每個新樣本緩沖區開始處理的入口。新的緩沖區樣本仍然需要衰減的可能性很大,所以f不適合每次都從1開始,而是應該在某種程度上繼承過去的值。即在每個新樣本緩沖區的入口處,只要f不等于1,就將其調整為比f稍大些的值,讓它成為新的衰減因子。若樣本的確不需要衰減,經過若干幀后f會慢慢變回1。 定點DSP中不易使用除法,所以可以把所有f的值做成一張表,f的取值范圍定義為1/16、2/16,直到15/16,它的衰減精度為1/16。當S發生箝位時,用比較法或者查表法求出合適f (15個取值之一)。之所以考慮是1/16的步長,是因為它已經可以確保16個輸入流求和不會溢出,如果還需要更大的精度,可以取1/32(2的n次方由定點DSP實現起來較方便)。 歸納起來,歸一化定標的核心思想是:f必須很快地變成合適的衰減因子,使得樣本不會溢出,然后f會慢慢地變回1。S發生箝位時f立刻被計算出,而在時間上每處理完一個求和幀后,就試圖把f向1靠近,f每次增加它與1的差值的1/16。即: f′= f+(1-f)/16。具體的定標流程圖如圖2所示。 3 試驗分析 同時輸入10路的音頻流到混音模塊,每路的采樣率都是16kHz,幀長選擇10ms,即160個樣本。 在對電干擾進行抵消時,對于帶寬為3kHz(300~3 300Hz)的寬帶隨機白噪聲,抵消程度優于42dB。在室外,其混響時間較小,對寬帶噪聲的聲干擾的抵消程度優于30dB。在混響較為嚴重的實驗室中,聲干擾的抵消程度也可以優于15dB。 經過聽覺試驗表明,經過定標和回波抑制的合成語音流輸出能夠清晰分辨出每一路的聲音。 使用Matlab比較對輸出進行簡單箝位和輸出定標兩種方式的語音時域波形,可以觀察到前者波形中有很多因溢出導致的“削波”,而后者的波形失真較小。 數字音頻流合成對于多點音頻會議系統是不可缺少的。首先對輸入的多路音頻流進行經過有無聲能量檢測和回波抑制處理后將有效輸入信號線性疊加,然后進行增益定標以便減少失真,以滿足輸出設備的要求。通過定點DSP的實現以及實驗證明這種模式下的音頻會議信號合成算法能取得很好的會議效果。 |