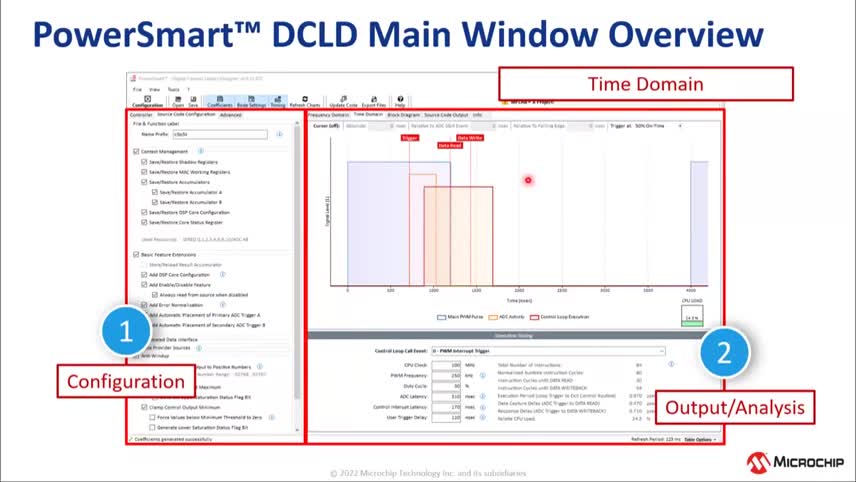
|
數據壓縮技術能減少傳輸所用的時間和存儲空間,在有限的信道容量內傳輸更多的有用信息,有助于降低功率和帶寬要求,改善通信效率。反之,如果不進行數據壓縮,則無論傳輸或存儲都很難實用化[1]。 1 硬件及實現原理 結合本設計的實際情況,由于壓縮算法比較復雜,計算量大,在壓縮數據時必須采用浮點型運算。另一方面,由于處理精度要求高,所以需要選擇浮點型DSP。基于上述考慮,選用TI公司的一款性價比非常高的浮點芯片TMS320C6713。其主頻225MHz,每周期執行8條32bit指令,最高定點運算能力為 1800MIPS,浮點運算能力為1350MFLOPS,32位指令集,而且內部自帶256KB的RAM,4KB程序緩沖器和4KB的數據緩沖器,可以通過外部存儲器接口EMIF(External Memory Inter Faces)擴展SDRAM和Flash[2]。在本設計中,對原始數據按照每2 048B為一組進行壓縮。壓縮的最小單位是2 048B,且壓縮率不固定,對于某組特定數據壓縮后可能比原來的數據還要大。壓縮前后的數據都需要放到DSP的RAM中進行處理,其256KB的RAM不能滿足本設計存儲要求,需要通過EMIF擴展存儲空間。SDRAM選用Micron公司的MT48LC2M32B2。其數據總線為32位,存儲空間為 64Mbit。工作電壓為3.3V,內部流水線結構保證了芯片的高速運行。SDRAM可以與EMIF無縫接口。EMIF的CE0連入片選引腳CS,將 SDRAM映射到CE0地址空間(0x80000000-0x80800000)。Flash是系統在斷電后用來保存程序和初始化數據的存儲器,系統上電時,由引導程序將DSP的應用程序從該存儲器引導到系統的高速存儲器RAM中。本設計用AMD公司生產的1M×8bit/512K×16bit AM29LV800-70 Flash存儲器,其數據寬度為8位、16位可選,采用3.3V供電,訪問時間僅70ns。EMIF的CE1連入片選引腳CE,將Flash映射到CE1 地址空間地址范圍為0x90000000~0x90100000,尋址空間為1MB[3]。 通常在高速數據采集系統中,數據處理速度及數據傳輸速度與前端A/D轉換器的采集速度不一致。為了協調它們之間工作,可以加入數據存儲器或者數據緩存器(FIFO)進行數據緩沖,使得前端數據采集和后級數據處理能夠協調工作。在本設計中,前端的采樣速度為27Kb/s;且數據流是連續的。DSP的主頻為 225MHz,經過鎖向環分頻后其讀取數據的速度為38Mb/s左右。DSP若一直等待讀數據,會大大降低其數據的處理能力。DSP讀入數據后,馬上對數據進行壓縮,壓縮后把相應的數據寫到輸出FIFO。同理,發送模塊的處理速度為18Kb/s。DSP寫輸出FIFO的速度也在38Mb/s左右。顯然,前端與DSP及DSP與發送模塊的處理速度不是一個數量級。所以在前端與DSP之間,DSP與發送模塊間分別加了兩個FIFO。本設計中FIFO1、 FIFO2均選用IDT72V19160,其存儲空間為128KB,16位并行數據總線,可達到100MHz的操作時鐘。原理框圖如圖1所示。 前端通過16位數據總線將數據寫入到輸入FIFO1中。在程序中通過控制其半滿(HF)信號,即當數據超過32KB時(32768+1), HF信號低電平有效,就會觸發一次中斷通知可編程邏輯和DSP,DSP進入中斷后把2KB的數據從輸入FIFO1中讀入到SBUF所指向的SDRAM空間中,在進行高速壓縮以后,被壓縮的數據放到DBUF中。SBUF的數據要與DBUF的數據進行比較,若DBUF中存儲數據的容量小于SBUF中的存儲數據的容量,就把DBUF中相應的數據寫到DSP的軟FIFO中,否則,就把SBUF中相應的數據寫到DSP的軟FIFO中。最終,DSP把壓縮后的數據通過其軟FIFO寫入到輸出FIFO2中,等待發送模塊把數據讀走。 在上述過程中,如果DSP沒有等待到中斷信號,則返回繼續等待,直到檢測到中斷信號,才讀取FIFO1中的數據。在DSP對SBUF中的數據幀壓縮的同時,前端以固定的采樣率對模擬信號進行采樣,并寫入到輸入FIFO1中。同時DSP把壓縮后的數據按每次小于2KB左右的速度寫入到輸出FIFO2。當輸出FIFO2半滿,發送模塊控制器會把其HF信號通過GPIO口指向DSP。本設計中用GP10實現相應的操作。DSP的GPIO口可以設為輸入引腳,在中斷向量表中定義后,其本身可以當作中斷使用。這樣DSP可以把采集到的實時數據源源不斷地寫入到FIFO2。整個信號處理模塊的不同子模塊都處于并行工作狀態,較好地實現了數據的實時壓縮,提高了壓縮效率。 設備上電DSP復位后,由其內部固化的自引導程序(BOOT)將存于Flash存儲器的程序和數據搬移至內部 RAM中,然后DSP即可以開始讀取壓縮算法的應用程序,繼續運行。DSP的工作流程圖如圖2所示。上電以后,首先初始化DSP的CSL函數庫,然后初始化PLL、GPIO及關中斷寄存器,等待中斷信號的來臨。 2 算法的選擇 無損壓縮就是對信源信息進行壓縮編碼后在解壓縮時能夠完全恢復,也即在壓縮和解壓縮過程中對信源信息沒有絲毫損失。常用的無損壓縮方法有Shannon- Fano編碼、Huffman編碼、游程(Run-length)編碼、LZW(Lempel-Ziv-Welch)編碼和算術編碼(ARC)等。對許多信息而言,沒必要完全保留全部特征。在允許一定精度損失的情況下,可以獲得更高的壓縮編碼效率。這類壓縮編碼方法成為有損壓縮。本設計采用無損壓縮,不再討論有損壓縮。 無損數據壓縮算法可以分為統計方法和詞典編碼方法。統計方法當以Huffman編碼和算術編碼(ARC)為代表。這種方法需要統計信源符號的概率分布情況,并根據統計結果產生壓縮碼。算術編碼是一種高效清除字串冗余的算法。仙儂信息論把字符aj出現的自信息量定義為I(aj)=-logpj I(aj)亦稱自信息函數,其含義實際是隨機變量X取值為aj時所攜帶信息的度量。自信息量的概率平均值,即隨機變量I(aj) 的數學期望值,稱做信息熵或簡稱熵。算術編碼從全序列出發,采用遞推形式連續編碼。它不是將單個的信源符號映射成一個碼字,而是將整個輸入符號序列映射為實數軸上[0,1)區間內的一個小區間,其長度等于該序列的概率,再在該小區間內選擇一個有代表性的二進制小數,而且是一個介于0和1之間的二進制小數作為實際的編碼輸出,從而達到了高效編碼的目的。例如算術編碼對某條信息的輸出為1010001111,它表示小數0.1010001111,也即十進制數 0.64。不論是否為二元信源,也不論數據的概率分布如何,其平均碼長均能逼近信源的熵。算術編碼的過程實際上也就是信源編碼試圖將任意的信息流與0、1 之間的間隔建立一一對應關系的過程。這樣要表示的信息流越長,則表示它的間隔就越小,用于表示這一間隔所需的二進制位就越多。 算術編碼在編碼前要求預先統計各信源符號概率,但無須排序,只要編、解碼端使用相同的符號順序即可。建立合理的信源概率模型是進行算術編碼的關鍵。信源概率模型的建立方法一般有兩種:一種是自適應的模型,是在不斷輸入信源的過程中對信源符號出現的概率進行統計,模型是在編碼過程中逐步建立起來并不斷更新;另一種是事先統計的模型,是在編碼前就對所有輸入信源符號的出現頻率進行事先統計,而編碼過程中模型不再改變。基于兩種模型算法的不同之處:事先統計模型在編碼之前就己經建立,編碼過程中不再更新,故壓縮效率與輸入字節數關系不大;而自適應模型是在編碼過程中建立并不斷更新,當輸入信源的數據量較大時,出現概率大的字符編碼位數較少的優越性才能得以體現。在復雜度上,由于后者需要不斷對模型進行更新,故運算量較大。 詞典編碼方法則是基于數據中許多結構頻繁重復再現這一事實,人們可以對相同符號串分配同一碼字、通過索引或者其他諸如此類的方法編碼。LZW算法可以在對數據統計特性一無所知的前提下,使壓縮率接近己知統計特性時所能夠達到的壓縮率,其運算速度快。LZW算法壓縮的原理在于用字典中詞條的編碼代替被壓縮數據中的字符串。字典中的詞條越長越多,壓縮率就越高。所以加大字典的容量可以提高壓縮率。但從字典中查找詞條是算法中最費時的工作,其字典的容量受到計算機內存限制,且字典也存在被填滿的可能。當字典不能再加入新詞條后,過老的字典就不能保證高的壓縮率。 不同的壓縮算法有不同的優點和缺點,不同算法的復雜性對空間的要求及壓縮率也不同。壓縮算法不僅僅依賴于壓縮方法本身,也依賴于被壓縮文本的特點。在本文中,由于是對實時數據的壓縮,對壓縮過程的時間性能要求高,所以采用事先統計模型的ARC。實驗證明,采用事先統計模型的ARC,其運算速度與LZW算法速度相近。而ARC算法在壓縮速度和壓縮去除率上都優于LZW算法。 3 實驗與結果 在比較字典編碼LZW與算術編碼ARC時,從壓縮速度和壓縮去除率上進行比較。前端以27Kb/s的速度實時采集8位的數據,數據壓縮后通過發送模塊以18Kb/s的速度數據傳到外界。對原始數據以2 048B作為分組長度考察其壓縮去除率及壓縮時間。 壓縮去除率=(原始數據量-壓縮后數據量)/原始數據量 這是從空間角度衡量。實際上,對壓縮效率而言還必須關注其時間效率,本文采用“壓縮速度”的概念,定義如下: 壓縮速度=原始數據量/壓縮所需要的時間以2 048B的數據分組進行分析: 1)從壓縮速度方面:完成2 048B的某噪聲數據,ARC算法需要5.64ms來完成,而LZW算法需要6.6ms,可見ARC算法的壓縮速度比較快。 (2)從壓縮效率方面:將某數據按照2 048B的長度進行分組并壓縮,從表1中可知ARC算法針對不同分組段的數據壓縮去除率恒定在78%左右,而LZW算法,在該分組段壓縮去除率僅為71%。可見該段數據ARC壓縮算法壓縮去除率比較高。 采用ARC算法后,通過大量的實驗數據的平均壓縮去除率為79%,滿足系統所要求的數據壓縮去除率大于50%的要求。用ARC算法壓縮2 048B的數據需要5.64ms左右。數據不同,壓縮時間會有所不同。通過對控制軟件讀取的數據進行解包、解壓,證明還原出來的數據與原始數據完全一致,實現了實時數據的無損壓縮。 |