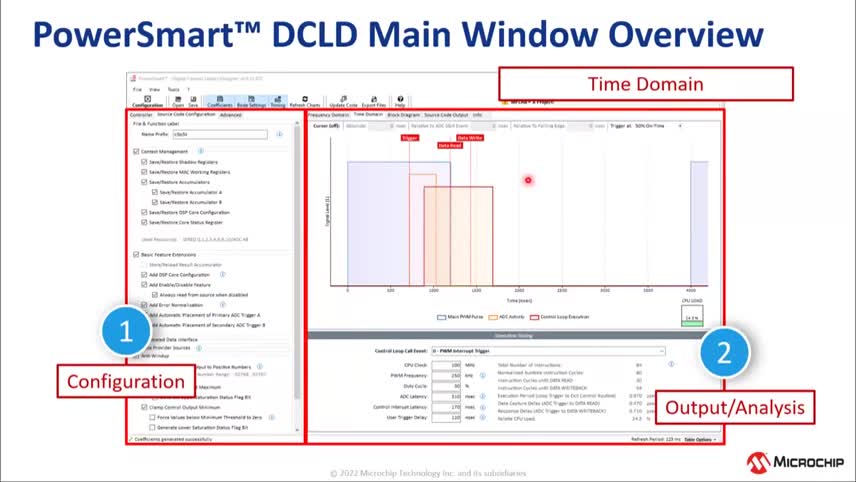
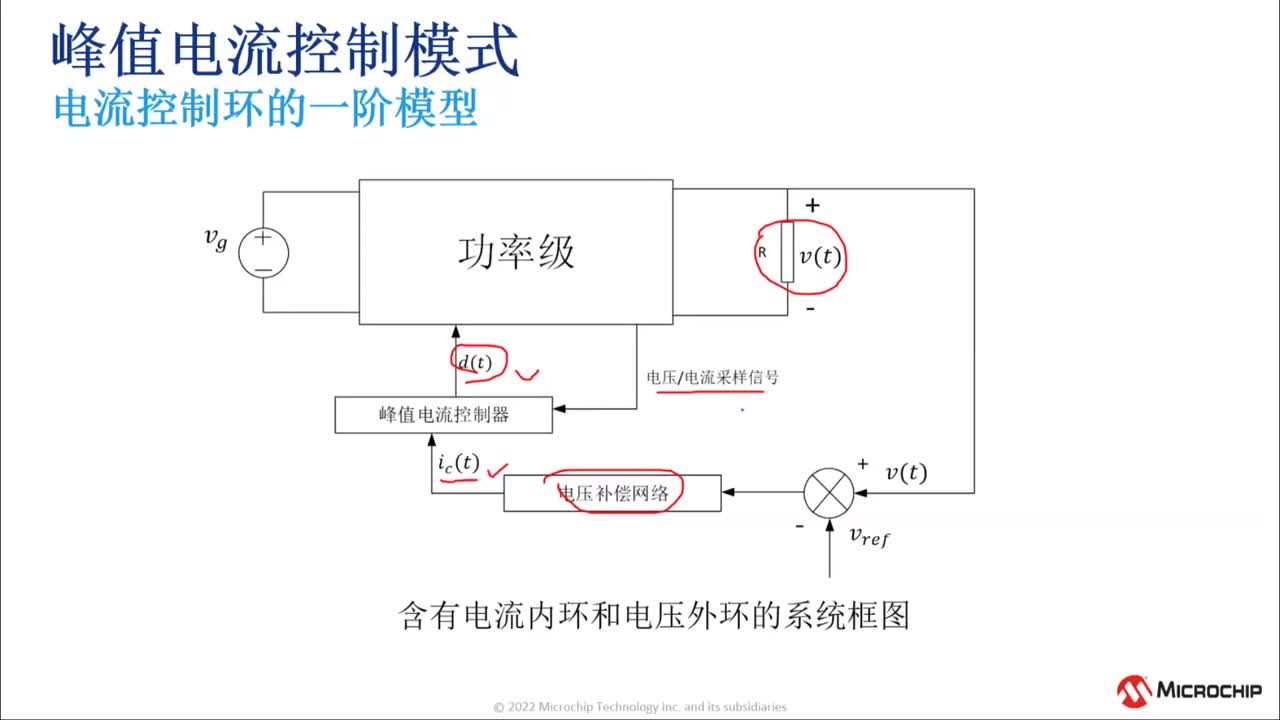
|
1 DSP系統的軟件優化流程 DSP系統的軟件優化流程如圖1所示。整個工作流程分為3個階段: 第1階段,直接根據需要用高級C語言實現DSP功能,測試代碼的正確性。然后,移植到C6X平臺,利用C6X開發環境Profile測試程序的運行時間。若不滿足要求,則進入下一階段。 第2階段,利用C6X提供的優化方式和其他各種優化技巧,如使用不同的編譯器選項使能軟件流水,循環展開,字存取代替半字存取等,優化C語言代碼。如果還不能滿足要求,則進入第3階段。 第3階段,將C語言代碼中耗時最長的部分抽取出來,用線性匯編語言重寫,用匯編優化器進行優化。使用profile確定這段代碼是否需要進一步優化。 2 優化過程 首先,用C語言編寫程序,并通過編譯驗證其正確性。然后,使用內聯函數和合適的優化選項進行優化,并通過CCS中的profiler確定是否有函數需要被進一步優化,使用線性匯編語言重寫需要被優化的函數。最后,使用匯編優化編程技巧和匯編優化器優化匯編代碼。 2.1 編譯器 當優化器被激活時,將完成圖2所示的過程。C/C++語言源代碼首先通過一個完成預處理的解析器(Parser),生成一個中間文件(.if)作為優化器(Optimizer)的輸入。優化器生成一個優化文件(.opt),這個文件作為完成進一步優化的代碼生成器(Code generator)的輸入,最終生成匯編文件(.asm)。當選擇編譯選項時,-o2和-o3將盡可能地優化軟件。 2.2 編譯器內聯函數 TMS320C6X提供了很多內聯函數,它們直接映射為內嵌C6X匯編指令的特殊函數,這樣可迅速優化C語言代碼。C編譯器以內聯函數的形式支持所有C語言代碼不易表達的指令。內聯函數用下劃線"_"開頭,如例2,使用時如同調用普通函數一樣。下面結合實例,研究一下完成200點點積經過上述各種優化技術優化后的代碼效率。完成200點的點積運算C語言代碼程序dotp.c如下: 3 線性匯編代碼的優化 優化線性匯編代碼,首先是盡可能地使指令并行,使得同一時間內多個功能單元同時被使用,然后是調整代碼順序,縮減等待時延(NOPS),如例5。接下來使用字訪問short型數據,如例6,最后使用軟件流水技術。當進行實際操作時,并不是要按順序地完成上面的每一步。只要達到要求,就可以結束。 3.1 C語言代碼轉換到線性匯編代碼 定點點積中,C語言代碼內部循環使用線性匯編指令,如例3所示。 3.2 線性匯編的資源分配 ①裝載指令(LDW)必須使用.D單元。 ②乘法指令(MPY和MPYH)必須使用.M單元。 ③加法指令(ADD)使用.L單元。 ④減法指令(SUB)使用.S單元。 ⑤跳轉指令(B)使用.S單元。 由此得到例4的匯編代碼。 完成200次循環迭代,經過profile clock分析循環部分,需要16×200=3200 cycles。 3.3 使用并行指令完成點積代碼 使用并行指令完成點積代碼如例5所示。 使用并行指令,循環體內需要8個時鐘周期。這段循環代碼的執行周期為8×200=1600 cycles。 3.4 使用字存取原short型數據 為進一步提高效率,使用字存取原short型數據,如例6所示。 這段代碼在循環體內仍然是8個時鐘周期,迭代100次為8×100=800 cycles。 4 軟件流水技術 軟件流水技術是用在循環語句中調用指令的方法,即安排循環中的多個迭代運算并行執行。在編譯C語言代碼時,可以選擇編譯器的-o2或-o3選項,編譯器將根據程序盡可能地安排軟件流水。圖3所示為運用軟件流水的循環結構,它包括A、B、C、D、E五次迭代,同一周期最多執行五次迭代的不同指令(陰影部分)。圖3中陰影部分稱為"循環內核",核中不同的指令并行執行。核前執行的過程稱為"流水線填充",核后執行的過程稱為"流水線排空"。 在DSP算法中存在大量的循環操作,因此充分運用軟件流水線方式,能極大地提高程序的運行速度。當手繪軟件流水時,首先要畫出相關圖,如圖4所示,然后建立軟件流水迭代間隔編排表,最后根據編排表寫出程序。 在畫相關圖時應遵循: ①畫出節點和路徑; ②寫出完成各指令需要的CPU周期; ③為各節點指派功能單元; ④分開路徑,以使最多的功能單元被使用。 根據相關圖寫出模迭代間隔安排表,如表1所列。 由此迭代間隔表寫出對應代碼: 由此得到的代碼所需CPU時鐘周期為7+100+l=108 cycles。 5 總 結 各種優化技術所需時鐘數如表2所列。表中括號內數字為循環內核時鐘周期,括號前數字為流水線填充時鐘周期,括號后數字為流水線排空CPU時鐘周期。 由此得出遵循以上的軟件優化流程和代碼優化技術,可以極大地提高代碼效率,這對實際應用具有重大意義。 |