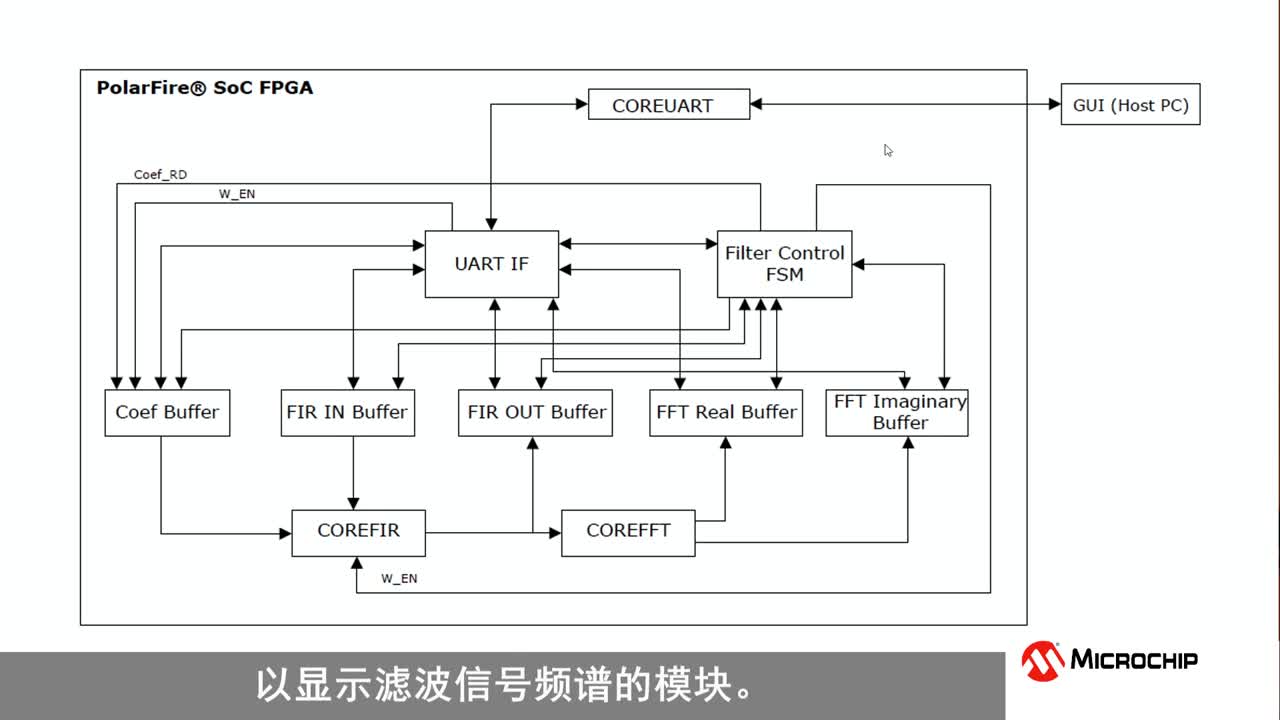
|
一般說來,SoC芯片是由片上芯核、用戶設計的IP核以及將這兩者集成在一起的總線組成的。片上芯核決定了使用何種片上總線以及芯片的體系結構。ARM系列嵌入式微處理器憑借其高性能、低功耗的特點占據了市場的主要份額,ARM7TDMI因其相對低廉的價格在SoC芯片設計中應用比較廣泛。同時,ARM公司開發的AMBA (Advanced Microprocessors Bus Architecture)片上總線架構由于其本身的高性能以及ARM核的廣泛應用,成為了一種流行的片上總線結構。除了片上芯核和片上總線,各種由用戶設計的或者由供應商提供的IP也集成在SoC芯片上。圖1是基于ARM7TDMI、面向消費電子領域的SoC芯片的模塊結構圖。 由圖1可知,ARM7TDMI需要通過總線訪問各個Slave;DMA工作時也需要通過總線訪問外設進行數據交換;而LCD控制器模塊為了實現實時顯示更是需要不斷地通過總線來訪問顯存讀取數據;系統中其他的Master在工作時也要占用總線。 特別要引起注意的是LCD控制器模塊。彩屏顯示需要很大的數據量,以一塊320×240、16bpp的TFT彩屏為例,其每一幀需要:320×240×16/8=153.6kByte。這么大的數據量不可能通過片上存儲器提供,勢必要通過存儲器接口從外設取得。由于LCD控制器所需要的數據量很大并且需要實時顯示,LCD控制器的工作將會占據大量的片上總線帶寬,甚至影響整個系統的正常運行。而在目前的消費電子領域,支持彩屏應用幾乎是不可缺少的。 解決此問題可以通過采用優化總線切換算法、增加片內Cache、改進總線架構等方法。其中,優化總線切換算法帶來的性能改善比較有限,而Cache本身設計的復雜性以及其License高昂費用,使之在很多情況下也不合適。因而,采用雙總線架構的AMBA不失為一個較好的選擇。 雙總線架構AMBA及其實現 在單層總線情況下,所有的Master和Slave都掛在AHB總線上。任何一個Master如果要訪問Slave的話,都必須先申請總線,在獲得總線所有權后,通過總線互聯結構中的MUX進行地址、數據和控制信號的交換,而其他的Master此時必須等待。 雙層AMBA總線結構 雙層AMBA總線架構則通過使用更為復雜的內部互聯結構,能夠同時有兩組Master和Slave通過AMBA進行數據的交互,極大地提高了總線的帶寬。而且任一個Master也都可以訪問任一層上的Slave。另外,在采用了雙層AMBA總線以后,對于AHB Master和AHB Slave來說是透明的,不需要任何的修改。 圖2是本文設計的雙層AMBA總線的內部結構圖。對于這個雙層AMBA總線,設置其能支持16個Master和16個Slave,并且每層各帶8個Master和8個Slave。 其中的雙層AMBA總線本身由三部分組成:Layer1的總線譯碼器、預仲裁器和多個數據選擇器(MUX);Layer2的總線譯碼器、預仲裁器和多個數據選擇器;整個總線的核心仲裁器(Arbiter)。其中,前二者基本是一致的,而核心仲裁器是整個雙層總線架構的核心。其原理是:每層的8個Master先在本層進行一次譯碼與仲裁,得到的結果送至核心仲裁器,再由核心仲裁器決定狀態的切換以及各個MUX如何進行數據流和控制流的選擇。 內部部件的設計 結合圖2和AMBA協議,以下介紹這個雙層AMBA總線的各個組成部件。由于第二層的各個部件的設計和功能和第一層相似,因而只介紹第一層。 * Layer1的譯碼器 該譯碼器采用集中式的地址譯碼機制,有利于提高外圍設備的可移植性。譯碼器接收到當前占用總線的Master所發出的地址信號,生成對應于各個Slave的片選信號,送給核心仲裁器。片選信號的生成是通過與各個Slave的基址比較得到的。 值得注意的是,由于每個Master都可以訪問Slave0~Slave15的任一個,所以譯碼器要能生成至少16個片選信號。 另外,每一層的譯碼器都應該要有一個缺省片選信號,對應于缺省Slave。這個缺省Slave的響應分兩種情況:對于IDLE或BUSY傳輸,作出OKAY回應;對于NONSEQU ENTIAL或SEQUENTIAL傳輸,作出ERROR回應。 * Layer1的預仲裁器 仲裁器接收各個Master發出的總線請求信號(HBusReq)和所需的總線切換的判斷信號,采用一定的總線仲裁算法,確定出可以占據總線的Master,并生成M to S MUX1的控制信號。與單層的AMBA不同,其生成的HMaster_layer1、BusHgrant_layer1信號送到核心仲裁器,而不是直接送給各個HMaster。另外,接收到的當前Slave響應是從核心仲裁器送出來的。 仲裁器可以采用的總線切換算法有兩種:固定優先級算法和循環優先級算法。在AMBA規范中,可以根據實際需要靈活選擇總線的切換算法。在這個部件里,采用了固定優先級的算法,即Master0優先級最低,而Master7優先級最高。 * Layer1的多路選擇器 在Layer1中共有4個MUX,分別是M to S MUX1、M to S MUX2、S to M MUX1和S to M MUX2。其中,M to S MUX1接收Layer1仲裁器的信號作為片選信號,從8組總線信號中選擇一組輸出給核心仲裁器、Layer1的M to S MUX2和Layer2的M to S MUX2。對于M to S MUX2,其控制信號是從核心仲裁器得到的,它的作用是從兩組總線信號中選擇一組送給Layer1中相應的Slave。而S to M MUX1則是接收核心仲裁器輸出的片選信號,從Layer1的8組總線響應信號(Hready、Hresp、Hrdata)選擇一組送給核心仲裁器、Layer1的S to M MUX2和Layer2的S to M MUX2。由S to M MUX2輸出一組總線響應信號給Layer1的所有的Master。 * 核心仲裁器 核心仲裁器的主要作用是:從兩層的譯碼器輸出的片選信號出發,得到初始狀態;再由Slave的響應信號以及傳輸狀態來決定何時進行狀態的切換;同時,根據自己所處的狀態,輸出相應信號給相關的MUX作為控制信號,輸出Hmaster、BusHgrant信號給每層的Master,以及輸出相應的Slave響應信號給兩層的預仲裁器。 由于存在不同層的Master同時訪問同一層的Slave的情況,核心仲裁器也要考慮總線切換算法。又因為在核心仲裁器里至多是兩個Master搶占總線,故可以采用簡單的循環優先級算法。 核心仲裁器的主要部分是一個狀態機,它由七個狀態組成: IDLE:系統復位后進入此狀態,完成部分數據的初始賦值; M1S1M2S2:Layer1的Master和Layer1的Slave通信,Layer2的Master和Layer2的Slave通信,即兩層總線并行運行; M1S2M2S1:Layer1的Master和Layer2的Slave通信,Layer2的Master和Layer1的Slave通信; M1S1M2S1:Layer1的Master和Layer1的Slave通信,Layer2的Master在等待和Layer1的Slave的通信; M1S2M2S2:Layer1的Master和Layer2的Slave通信,Layer2的Master在等待和Layer2的Slave的通信; M2S1M1S1:Layer2的Master和Layer1的Slave通信,Layer1的Master在等待和Layer1的Slave的通信; M2S2M1S2:Layer2的Master和Layer2的Slave通信,Layer1的Master在等待和Layer2的Slave的通信。 這七個狀態之間的切換是由兩層譯碼器給出的片選信號、當前占據總線的Master發出的控制信號以及與此Master通信的Slave的響應信號共同決定的。當涉及到ARM Master的狀態切換,需考慮三級流水線特性,給予適當的等待周期。 另外,在核心仲裁器里還有一級輸入鎖存部分,用于鎖存正在等待的Master發出的地址和控制信號。 設計結果以及測試平臺的建立 對于以上實現,采用Verilog語言在RTL級進行描述,使用Synopsys的VCS工具進行功能仿真。為了驗證以上設計的正確性,針對圖1所示的架構,把單層AMBA改為雙層的AMBA,并把LCDC Master和LCDC Slave移至第二層。同時在第二層增加了一個簡單的MC Slave,并在其外面掛了SRAM、SDRAM的存儲器模型,其中的SDRAM用于LCDC Master顯存數據的存放,其他的結構保持不變(如圖3)。同時,還準備了一套基于ARM匯編語言的測試程序進行系統的配置。在這個測試程序運行以后,共有三個Master:ARM Master、DMA Master和LCDC Master會不斷訪問總線。 結果表明設計是正確的:ARM Master可以對Layer2的Slave進行配置;在第二層的LCDC Master從同層的MC Slave讀數據的同時,第一層的Master正在訪問同層的Slave;Layer1的其他Master也能夠申請到Layer2的總線以訪問Layer2的外存。 另外,為了考察LCD控制器對總線的占用率,在AHB上掛了一個Hmaster Monitor的子模塊,用于統計各個Master占據當前總線的時鐘周期數。 兩種總線方式的比較 從兩個方面比較單層AMBA總線與雙層AMBA總線的設計。 首先,從降低LCD控制器總線占用率方面看。由表1可以看出,在使用單層AMBA總線的情況下,LCD控制器占用的總線帶寬都比較大:對于典型的320×240、16bpp的TFT彩屏,LCD控制器占用了16.3%的總線帶寬。使用雙層AMBA總線時,除了ARM Master 對兩個Slave進行配置要占總線周期以外,LCD控制器將只會占用Layer2的帶寬。 其次,從綜合的結果看,雙層AMBA占用的面積要大一些。在包括APB模塊的情況下,單層AMBA綜合得到的面積為17000門,而雙層AMBA的面積為18500門。兩者都支持16個Master和16個Slave。采用TSMC 0.25工藝標準單元庫,使用Synopsys的Design Compiler工具進行門級網表的綜合。 對于雙層AMBA總線的實際的應用,可以把Layer1的MC Slave外接非易失性存儲器,而Layer2的MC Slave外接易失性存儲器。這樣,可以把指令區置于Layer1,而數據區置于Layer2。于是,ARM Master的取指操作就可以在Layer1完成,而LCD控制器對顯存數據的讀取則在Layer2完成。而這兩者恰恰是占總線帶寬很大的操作,因而很大程度上減少了各個Master因為總線搶占而等待的時間,提高了總線帶寬。 結語 ARM7TDMI在SoC芯片的設計中得到了極大的應用,但由于其自身不帶Cache,使之需要頻繁訪問外存。如果此時片上集成了其他需要很大數據帶寬的模塊,就會使系統的性能大幅下降。而雙層AMBA總線在占用面積略為增加的條件下,能極大地提高總線帶寬,并且提供了更為靈活的系統架構。這對于基于ARM7TDMI的SoC芯片以及其他類似架構的SoC芯片來說,有著很重要的意義和實用價值。 |