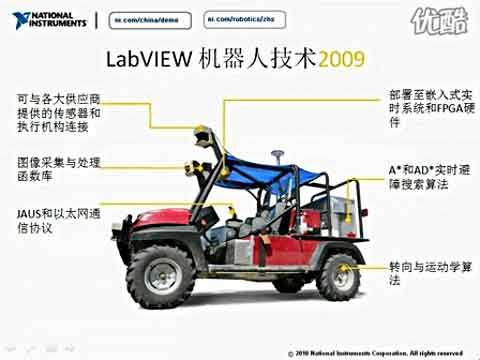
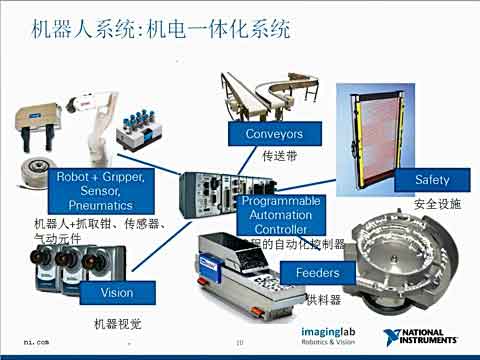
|
作者:Arm 物聯網事業部業務拓展副總裁 馬健 你聽過莫拉維克悖論 (Moravec's paradox) 嗎?該悖論指出,對于人工智能 (AI) 系統而言,高級推理只需非常少的計算能力,而實現人類習以為常的感知運動技能卻需要耗費巨大的計算資源。實質上,與人類本能可以完成的基本感官任務相比,復雜的邏輯任務對 AI 而言更加容易。這一悖論凸顯了現階段的 AI 與人類認知能力之間的差異。 人本來就是多模態的。我們每個人就像一個智能終端,通常需要去學校上課接受學識熏陶(訓練),但訓練與學習的目的和結果是我們有能力自主工作和生活,而不需要總是依賴外部的指令和控制。 我們通過視覺、語言、聲音、觸覺、味覺和嗅覺等多種感官模式來了解周圍的世界,進而審時度勢,進行分析、推理、決斷并采取行動。 經過多年的傳感器融合和 AI 演進,機器人現階段基本上都配備有多模態傳感器。隨著我們為機器人等邊緣設備帶來更多的計算能力,這些設備正變得愈加智能,它們能夠感知周圍環境,理解并以自然語言進行溝通,通過數字傳感界面獲得觸覺,以及通過加速計、陀螺儀與磁力計等的組合,來感知機器人的比力、角速度,甚至機器人周圍的磁場。 邁入機器人和機器認知的新時代 在 Transformer 和大語言模型 (LLM) 出現之前,要在 AI 中實現多模態,通常需要用到多個負責不同類型數據(文本、圖像、音頻)的單獨模型,并通過復雜的過程對不同模態進行集成。 而在 Transformer 模型和 LLM 出現后,多模態變得更加集成化,使得單個模型可以同時處理和理解多種數據類型,從而產生對環境綜合感知能力更強大的 AI 系統。這一轉變大大提高了多模態 AI 應用的效率和有效性。 雖然 GPT-3 等 LLM 主要以文本為基礎,但業界已朝著多模態取得了快速進展。從 OpenAI 的 CLIP 和 DALL·E,到現在的 Sora 和 GPT-4o,都是向多模態和更自然的人機交互邁進的模型范例。例如,CLIP 可理解與自然語言配對的圖像,從而在視覺和文本信息之間架起橋梁;DALL·E 旨在根據文本描述生成圖像。我們看到 Google Gemini 模型也經歷了類似的演進。 2024 年,多模態演進加速發展。今年二月,OpenAI 發布了 Sora,它可以根據文本描述生成逼真或富有想象力的視頻。仔細想想,這可以為構建通用世界模擬器提供一條頗有前景的道路,或成為訓練機器人的重要工具。三個月后,GPT-4o 顯著提高了人機交互的性能,并且能夠在音頻、視覺和文本之間實時推理。綜合利用文本、視覺和音頻信息來端到端地訓練一個新模型,消除從輸入模態到文本,再從文本到輸出模態的兩次模態轉換,進而大幅提升性能。 在今年二月的同一周,谷歌發布了 Gemini 1.5,將上下文長度大幅擴展至 100 萬個詞元 (Token)。這意味著 1.5 Pro 可以一次性處理大量信息,包括一小時的視頻、11 小時的音頻、包含超過三萬多行代碼或 70 萬個單詞的代碼庫。Gemini 1.5 基于谷歌對 Transformer 和混合專家架構 (MoE) 的領先研究而構建,并對可在邊緣側部署的 2B 和 7B 模型進行了開源。在五月舉行的 Google I/O 大會上,除了將上下文長度增加一倍,并發布一系列生成式 AI 工具和應用,谷歌還探討了 Project Astra 的未來愿景,這是一款通用的 AI 助手,可以處理多模態信息,理解用戶所處的上下文,并在對話中非常自然地與人交互。 作為開源 LLM Llama 背后的公司,Meta 也加入了通用人工智能 (AGI) 的賽道。 這種真正的多模態性大大提高了機器智能水平,將為許多行業帶來新的范式。 例如,機器人的用途曾經非常單一,它們具備一些傳感器和運動能力,但一般來說,它們沒有“大腦”來學習新事物,無法適應非結構化和陌生環境。 多模態 LLM 有望改變機器人的分析、推理和學習能力,使機器人從專用轉向通用。PC、服務器和智能手機都是通用計算平臺中的佼佼者,它們可以運行許多不同種類的軟件應用來實現豐富多彩的功能。通用化將有助于擴大規模,產生規模化的經濟效應,價格也能隨著規模擴大而大幅降低,進而被更多領域采用,從而形成一個良性循環。 Elon Musk 很早就注意到了通用技術的優勢,特斯拉的機器人從 2022 年的 Bumblebee 發展到 2023 年三月宣布的 Optimus Gen 1 和 2023 年年底的 Gen 2,其通用型和學習能力不斷提高。在過去的 6 至 12 個月里,我們見證了機器人和人形機器人領域所取得的一系列突破。 下一代機器人和具身智能背后的新技術 毋庸置疑的是我們在具身智能達到量產方面還有很多工作要做。我們需要更輕便的設計、更長的運行時間,以及速度更快、功能更強大的邊緣計算平臺來處理和融合傳感器數據信息,從而做出及時決策和控制行動。 而且我們正朝著創造人形機器人的方向發展,人類文明數千年,產生出無處不在的專為人類設計的環境,而人形機器人系統由于形體與人們類似,有望能夠在人類生存的環境中駕輕就熟地與人類和環境互動并執行所需的操作。這些系統將非常適合處理臟污、危險和枯燥的工作,例如患者護理和康復、酒店業的服務工作、教育領域的教具或學伴,以及進行災難響應和有害物質處理等危險任務。此類應用利用人形機器人類人的屬性來促進人機自然交互,在以人為中心的空間中行動,并執行傳統機器人通常難以完成的任務。 許多 AI 和機器人企業圍繞如何訓練機器人在非結構化的新環境中更好地進行推理和規劃,展開了新的研究與協作。作為機器人的新“大腦”,預先經過大量數據訓練的模型具有出色的泛化能力,使得機器人能做到見怪不怪,更全面地理解環境,根據感官反饋調整動作和行動,在各種動態環境中優化性能。 舉一個有趣的例子,Boston Dynamics 的機器狗 Spot 可以在博物館里當導游。Spot 能夠與參觀者互動,向他們介紹各種展品,并回答他們的問題。這可能有點難以置信,但在該用例中,比起確保事實正確,Spot 的娛樂性、互動性和細膩微妙的表演更加重要。 Robotics Transformer:機器人的新大腦 Robotics Transformer (RT) 正在快速發展,它可以將多模態輸入直接轉化為行動編碼。在執行曾經見過的任務時,谷歌 DeepMind 的 RT-2 較上一代的 RT-1 表現一樣出色,成功率接近 100%。但是,使用 PaLM-E(面向機器人的具身多模態語言模型)和 PaLI-X(大規模多語言視覺和語言模型,并非專為機器人設計)訓練后,RT-2 具有更出色的泛化能力,在未曾見過的任務中的表現優于 RT-1。 微軟推出了大語言和視覺助手 LLaVA。LLaVA 最初是為基于文本的任務設計的,它利用 GPT-4 的強大功能創建了多模態指令遵循數據的新范式,將文本和視覺組件無縫集成,這對機器人任務非常有用。LLaVA 一經推出,就創下了多模態聊天和科學問答任務的新紀錄,已超出人類平均能力。 正如此前提到的,特斯拉進軍人形機器人和 AI 通用機器人領域的意義重大,不僅因為它是為實現規模化和量產而設計的,而且因為特斯拉為汽車設計的 Autopilot 的強大完全自動駕駛 (FSD) 技術基礎可用于機器人。特斯拉也擁有智能制造用例,可以將 Optimus 應用于其新能源汽車的生產過程。 Arm 是未來機器人技術的基石 Arm 認為機器人腦,包括“大腦”和“小腦”,應該是異構 AI 計算系統,以提供出色的性能、實時響應和高能效。 
機器人技術涉及的任務范圍廣泛,包括基本的計算(比如向電機發送和接收信號)、先進的數據處理(比如圖像和傳感器數據解讀),以及運行前文提到的多模態 LLM。CPU 非常適合執行通用任務,而 AI 加速器和 GPU 可以更高效地處理并行處理任務,如機器學習 (ML) 和圖形處理。還可以集成圖像信號處理器和視頻編解碼器等額外加速器,從而增強機器人的視覺能力和存儲/傳輸效率。此外,CPU 還應該具備實時響應能力,并且需要能夠運行 Linux 和 ROS 軟件包等操作系統。 當擴展到機器人軟件堆棧時,操作系統層可能還需要一個能夠可靠處理時間關鍵型任務的實時操作系統 (RTOS),以及針對機器人定制的 Linux 發行版,如 ROS,它可以提供專為異構計算集群設計的服務。我們相信,SystemReady 和 PSA Certified 等由 Arm 發起的標準和認證計劃將幫助擴大機器人軟件的開發規模。SystemReady 旨在確保標準的 Rich OS 發行版能夠在各類基于 Arm 架構的系統級芯片 (SoC) 上運行,而 PSA Certified 有助于簡化安全實現方案,以滿足區域安全和監管法規對互聯設備的要求。 大型多模態模型和生成式 AI 的進步預示著 AI 機器人和人形機器人的發展進入了新紀元。在這個新時代,要使機器人技術成為主流,除了 AI 計算和生態系統,能效、安全性和功能安全必不可少。Arm 處理器已廣泛應用于機器人領域,我們期待與生態系統密切合作,使 Arm 成為未來 AI 機器人的基石。 |