|
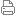
transformers的近期工作成果綜述基于 transformer 的雙向編碼器表示(BERT)和微軟的圖靈自然語言生成(T-NLG)等模型已經(jīng)在機(jī)器學(xué)習(xí)世界中廣泛的用于自然語言處理(NLP)任務(wù),如機(jī)器翻譯、文本摘要、問題回答、蛋白質(zhì)折疊預(yù)測,甚至圖像處理任務(wù)。 在本文中,對基于transformer 的工作成果做了一個簡單的總結(jié),將最新的transformer 研究成果(特別是在2021年和2022年發(fā)表的研究成果)進(jìn)行詳細(xì)的調(diào)研。 這張圖與一篇調(diào)查論文[Tay 2022]中的圖相似,但被調(diào)transformers會更新并且它們的整體分類也有很大的不同。 如圖所示,主要類別包括計算復(fù)雜度、魯棒性、隱私性、近似性和模型壓縮等等。本文文字和專業(yè)術(shù)語較多,并且均翻譯自論文原文,如有錯誤(很可能)請諒解。 計算復(fù)雜度一些研究方向是以各種方式解決transformer的O(N2)計算復(fù)雜度。transformer的關(guān)鍵問題之一是它與輸入序列長度相關(guān)的二次復(fù)雜度。這意味著我們必須為每一層和注意頭計算N*N個注意矩陣。人們嘗試了各種方法來降低這種O(N2)復(fù)雜度,包括使用緩存體系結(jié)構(gòu)。 Sparse transformer是解決這種復(fù)雜性的流行方法之一。每個輸出位置從輸入位置的一個子集計算權(quán)重。如果子集是√(N),那么transformer的復(fù)雜度降低到O(N *√(N)),并允許它處理更大范圍的依賴關(guān)系。 Longformer使用了帶窗口的局部注意力(對于窗口大小為w的窗口,每個令牌會注意到兩邊的w/2個令牌,而不是整個輸入)并且使用特殊令牌的任務(wù)驅(qū)動的全局注意力進(jìn)行組合。 另一項(xiàng)被稱為BigBird [Manzil 2020]的工作使用了圖稀疏化技術(shù)。它使用一種稱為Watts-Strogatz圖的特殊圖,它近似于一個完整的圖可以實(shí)現(xiàn)輸入序列的線性復(fù)雜度。作者表明在標(biāo)準(zhǔn)精度假設(shè)下,BigBird是圖靈完備的。他們還評估BigBird在遠(yuǎn)距離依賴的任務(wù)上的表現(xiàn),特別是在提取基因組序列(如DNA)和預(yù)測結(jié)果染色質(zhì)譜方面 Linformer使用線性投影和低秩因子分解的組合逼近點(diǎn)積注意運(yùn)算[Wang2020]。 上面許多基于稀疏矩陣操作的transformer可能需要稀疏矩陣乘法操作,這種方式并不是在所有體系結(jié)構(gòu)上都可用。他們也傾向于堆疊更多的注意力層來彌補(bǔ)稀疏性,從而導(dǎo)致總體上的算力的增加。對于某些操作,如softmax操作也可能不容易;還有多項(xiàng)式probit運(yùn)算也不容易稀疏化。 谷歌提出了一個廣義注意框架Performer,可以根據(jù)不同的相似性度量或內(nèi)核來指定廣泛的注意力機(jī)制。他們通過積極的正交隨機(jī)特征(Favor+)算法來實(shí)現(xiàn)注意力的機(jī)制。他們還表明可以通過指數(shù)函數(shù)和隨機(jī)高斯投影的組合來近似普通的softmax注意。Performer在蛋白質(zhì)序列預(yù)測任務(wù)等方面優(yōu)于標(biāo)準(zhǔn)模型。 Wang等[Wang 2021]提出了一種用于無卷積的密集預(yù)測的金字塔視覺transformer(PVT)。這一問題克服了基于VIT的模型在將密集的預(yù)測任務(wù)時遇到了困難,PVT有助于各種像素級密度預(yù)測,并且不需要卷積和非最大抑制,如目標(biāo)檢測方法。采用漸進(jìn)式收縮金字塔和空間減少注意力可以很容易地連接transformer。最后在圖像分類、目標(biāo)檢測、實(shí)例和語義分割等任務(wù)中PVT也是可用的。 Liu等人[Liu 2021]討論了transformer從語言領(lǐng)域到視覺領(lǐng)域的適應(yīng)問題,方法包括大量視覺實(shí)體的差異和與文本中的文字相比的圖像的高分辨率像素差異。為了解決這個問題,作者提出了Swin Transformer [Lui 2021],這是一種分層方法,其表示是使用移位窗口計算。該技術(shù)更有效地克服了自注意力局部窗口不重疊的問題。 Chu等人[Chu 2021]討論了空間注意對于transformer在各種任務(wù)中的性能成功的重要性。作者提出了兩個簡單而高效的體系結(jié)構(gòu):twin - pcpvt和twin - svt。twin -pcpvt使用可分離的深度卷積注意機(jī)(depth-wise convolution attention machine),又被稱為空間分離自注意力(spatial-separable self-attention - SSSA)。SSSA使用兩種類型的注意力操作:本地分組的自注意力(LSA)和全局次采樣的注意力(GSA)。LSA處理細(xì)粒度和短距離信息,而GSA則處理長距離序列和全局信息。另一個方法twin - svt同時使用LSA和帶有矩陣乘法的GSA。 光譜的復(fù)雜性通過將自注意網(wǎng)絡(luò)替換為混合輸入令牌的線性轉(zhuǎn)換,可以設(shè)計高效的transformer來加速編碼器架構(gòu)。transformer的自注意層被參數(shù)化的傅里葉變換(Fnet)取代[Lee-Thorp 2022],然后是一個非線性和前饋網(wǎng)絡(luò)。與BERT相比,該網(wǎng)絡(luò)速度快80%,可以達(dá)到傳統(tǒng)transformer性能的92%到97%。 The Global Frequency network(GFnet) [Rao 2022]提出了一種用于令牌混合的深度全局卷積。GFnet涉及三個步驟:通過快速傅里葉變換(FFT)進(jìn)行空間令牌混合、頻率門控和反FFT進(jìn)行令牌分解。GFnet不涉及信道混合,隨著序列長度的增加,對于高像素的圖像來說消耗非常大,而且不具有自適應(yīng)能力。 Guibias等人[Guibias 2022]將令牌混合任務(wù)定義為一種操作符學(xué)習(xí)任務(wù),該任務(wù)是學(xué)習(xí)在無限尺寸空間中連續(xù)函數(shù)之間的映射。Li等人[Li 2020]討論了使用傅里葉神經(jīng)算符(FNO)求解偏微分方程(PDE)。FNO在連續(xù)域中工作良好。 將FNO應(yīng)用于高分辨率圖像輸入的視覺域,需要對PDE的FNO設(shè)計體系結(jié)構(gòu)進(jìn)行修改。這是因?yàn)楦叻直媛穲D像由于邊緣和其他結(jié)構(gòu)而具有不連續(xù)性。信道混合FNO與信道大小有關(guān),具有二次復(fù)雜度。信道混合權(quán)重采用塊對角線結(jié)構(gòu)來解決信道混合問題。作者在MLP層的令牌之間共享權(quán)重以提高參數(shù)效率,并使用軟閾值在頻域引入稀疏性以進(jìn)行泛化。這些解決方案結(jié)合稱為自適應(yīng)傅里葉神經(jīng)算子(AFNO)。 Bai等人[Bai 2022]提出了HAT方法(High-frequency components via Adversarial Training),該方法在訓(xùn)練階段對組件進(jìn)行高頻擾動。HAT方法通過添加對抗性擾動改變訓(xùn)練圖像的高頻成分,然后用改變后的圖像訓(xùn)練ViT [Bai 2022]模型,這樣可以提高模型性能,使模型更魯棒。 魯棒性Shao等[Shao 2021]利分析了transformer模型的魯棒性。作者使用白盒攻擊進(jìn)行了一個實(shí)驗(yàn)。他們觀察到與卷積神經(jīng)網(wǎng)絡(luò)(CNNs)相比,ViT具有更好的對抗魯棒性。ViT特征包含低層信息,對對抗攻擊提供了優(yōu)越的魯棒性,并指出與增加尺寸或增加層數(shù)的純transformer模型相比,cnn和transformer的組合具有更好的魯棒性。他們還發(fā)現(xiàn)預(yù)訓(xùn)練更大的數(shù)據(jù)集并不能提高魯棒性。對于一個穩(wěn)健的模型,情況正好相反。 Bhojanapalli等人[Bhojanapalli 2021]調(diào)查了ViT模型和resnet模型針對對抗實(shí)例、自然實(shí)例和常見破壞的各種魯棒性度量。作者研究了對輸入和模型擾動的魯棒性。無論是從輸入還是從模型中去除任何一層,transformer都是魯棒的。 Paul等人[Paul 2022]研究了ViT [Dosovitskiy 2020]、cnn和Big Transformer[Kolesnikov 2020]方法的魯棒性。Paul等人[Paul 2022]在ImageNet數(shù)據(jù)集上對ViTs的魯棒性進(jìn)行了基準(zhǔn)測試。結(jié)果在表r中。通過6個實(shí)驗(yàn),作者驗(yàn)證了與CNN和Big Transformer相比,ViT在魯棒性方面有了提高。這些實(shí)驗(yàn)的結(jié)果包括: 實(shí)驗(yàn)1:注意力是提高魯棒性的關(guān)鍵。 實(shí)驗(yàn)2:預(yù)訓(xùn)練的作用很重要。 實(shí)驗(yàn)3:ViT對圖像遮蔽具有較好的魯棒性。 實(shí)驗(yàn)4:傅里葉頻譜分析顯示ViT的靈敏度較低。 實(shí)驗(yàn)5:對抗性擾動在能量譜中擴(kuò)散得更廣。 實(shí)驗(yàn)6:ViT對輸入擾動有更平滑的損失。 根據(jù)Park等人[Park 2022]的研究,與cnn相比ViT [Dosovitskiy 2020]在捕獲圖像高頻成分方面的效率較低。HAT [Bai 2022]是對現(xiàn)有transformer模型在頻率角度的影響進(jìn)行進(jìn)一步研究的結(jié)果。HAT使用RandAugment方法對輸入圖像的進(jìn)行高頻分量擾動。Wu等人[Wu 2022]研究了易受對抗實(shí)例影響的transformer模型的問題。這個問題(對對抗性噪聲的脆弱性)在cnn中是通過對抗性訓(xùn)練來處理的。但在transformer中,由于自注意計算的二次復(fù)雜度,對抗訓(xùn)練的計算成本很高。AGAT方法采用了一種有效的注意引導(dǎo)對抗機(jī)制,在對抗訓(xùn)練過程中使用注意引導(dǎo)下降策略去除每一層嵌入的確定性補(bǔ)丁。 隱私預(yù)訓(xùn)練的transformer模型部署在云上。基于云的模型部署中的一個主要問題與數(shù)據(jù)中隱私問題有關(guān)。主要的隱私問題是用戶數(shù)據(jù)(如搜索歷史、醫(yī)療記錄和銀行賬戶)的暴露。目前的研究重點(diǎn)是在transformer模型推理中保護(hù)隱私。 論文[Huang 2020]介紹了TextHide,一種保護(hù)隱私的聯(lián)邦學(xué)習(xí)技術(shù),但這種方法適用于基于句子的任務(wù),如機(jī)器翻譯、情緒分析、轉(zhuǎn)述生成任務(wù)),而不是基于令牌的任務(wù)(如名稱實(shí)體識別和語義角色標(biāo)記)。 DP-finetune [Kerrigan 2020]差分隱私(DP)方法允許量化保護(hù)數(shù)據(jù)敏感性的程度。但是訓(xùn)練DP算法會降低模型的質(zhì)量,但是可以在私有數(shù)據(jù)集上使用公共基礎(chǔ)模型進(jìn)行調(diào)優(yōu)來部分解決。 Gentry等人[Gentry 2009]提出了一種用homomorphic encryption(HE)中的密文保護(hù)隱私的方法。但是transformer的模型中GELU [Hendrycks 2016]激活的計算復(fù)雜性,HE解決方案只支持加法和乘法。 論文[Chen 2022]在transformer中基于HE [Boemer 2019, Boemer 2020]的解上提出了一種通過級數(shù)逼近的The - x方法。the - x方法在SoftMax和GELU等層的幫助下,用一系列近似代替非多項(xiàng)式操作,去掉池器層,添加歸一化層,使用知識蒸餾技術(shù)。THE-X方法使用BERT-Tiny Model進(jìn)行評估[Wang 2018],并對CONLL2003 [Sang2003]任務(wù)進(jìn)行了基準(zhǔn)測試。 Li等人[Li 2022]使用差分隱私算法解決了性能下降和高計算開銷的問題。這樣可以使用更大的預(yù)訓(xùn)練語言模型來處理,也可以通過在中等語料庫上使用DP優(yōu)化進(jìn)行微調(diào)的對齊預(yù)訓(xùn)練過程來進(jìn)行微調(diào)。 近似性論文[Ruthotto 2019]是最早為ResNets等深度神經(jīng)網(wǎng)絡(luò)提供基于偏微分方程(PDEs)的理論基礎(chǔ)的論文之一。更具體地說,作者證明了殘差cnn可以解釋為時空微分方程的離散化。在理論表征的基礎(chǔ)上,Ruthotto還提出了具有特殊性質(zhì)的雙曲和拋物線cnn等新模型。 殘差網(wǎng)絡(luò)也被解釋為常微分方程的歐拉離散化。但歐拉法求解精度不高,由于是一階方法,存在截斷誤差。ODE Transformers [Bei 2022]的作者使用了經(jīng)典的高階方法(Runge Kutta)來構(gòu)建Transformer塊。他們在三個序列生成任務(wù)上評估了ODE Transformers 。這些任務(wù)證明了ODE是有效的,包括抽象摘要、機(jī)器翻譯和語法糾正。在這個方向上的另一項(xiàng)努力是TransEvolve [Dutta 2021],它提供了一個Transformer架構(gòu),與ODE類似,但以多粒子動態(tài)系統(tǒng)為模型。 Transformers 已經(jīng)被證明相當(dāng)于通用計算引擎[Kevin 2022]。作者提出了一種稱為Frozen pretrain transformer (FPT)的結(jié)構(gòu),它可以在單一模態(tài)(如用于語言建模的文本數(shù)據(jù))上進(jìn)行訓(xùn)練,并識別跨模態(tài)有用的抽象(如特征表示)。他們采用GPT,只對自然語言數(shù)據(jù)進(jìn)行預(yù)訓(xùn)練,并對其輸入和輸出層以及層歸一化參數(shù)和位置嵌入進(jìn)行微調(diào)。這使得FPT在完成蛋白質(zhì)折疊預(yù)測、數(shù)值計算甚至圖像分類等各種任務(wù)時,可以與完全從零開始訓(xùn)練的transformer進(jìn)行比較。 模型壓縮
Touvron等人[Touvron 2021]提出了一種基于蒸餾技術(shù)(Deit)的高效transformer模型。它使用一種依賴于蒸餾令牌的師生策略,以確保學(xué)生通過注意力從老師那里學(xué)習(xí)。 Bao等人[Bao 2021]向預(yù)訓(xùn)練的VIT提出了一個遮蔽圖像模型任務(wù)。作者提出了一種基于自監(jiān)督的視覺表示模型,即來自圖像transformer的雙向編碼器表示(BEiT),它遵循了為自然語言處理領(lǐng)域開發(fā)的BERT [Kenton 2019]方法。在這種方法中,每個圖像被認(rèn)為是兩個視圖:一個是大小為16 x 16像素的圖像補(bǔ)丁,另一個是離散的可視標(biāo)記。將原始圖像標(biāo)記為可視標(biāo)記,并對部分圖像補(bǔ)丁進(jìn)行隨機(jī)掩碼,然后將其饋送給預(yù)訓(xùn)練的骨干transformer。訓(xùn)練BEiT后,模型可以針對下游任務(wù)進(jìn)行微調(diào)。 學(xué)習(xí)和關(guān)注人工智能技術(shù)與咨詢,更多詳情可咨詢175-3102-1189(v同號)。
| 






 發(fā)表于 2022-10-19 10:47:35
發(fā)表于 2022-10-19 10:47:35
 收藏
收藏 頂
頂 踩
踩