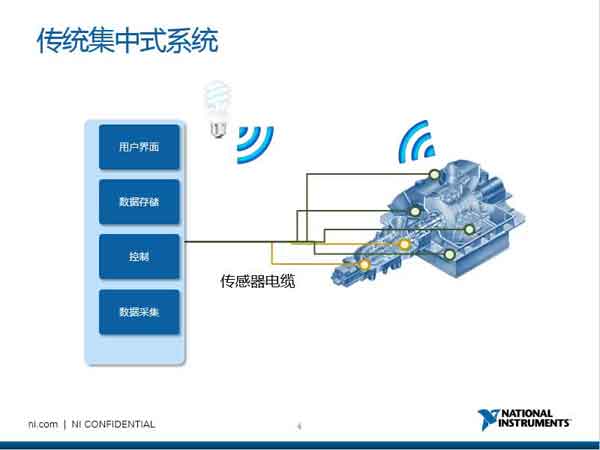
|
“分析”是一個非常普通的術語,用于關聯和消化原始數據以產生更有用的結果。分析算法可以簡單到就像數據規約或對一連串傳感器讀數求平均值,也可以復雜到就像最錯綜復雜的人工智能或機器學習 (AI/ML) 系統。如今,分析通常在云端執行,因為它是最具可擴展性和成本效益的解決方案。但在未來,分析將越來越多地分散到云、邊緣計算和端點設備上,以利用它們改進的延遲、網絡帶寬、安全性和可靠性。在這里,我們將討論把分析功能分布到傳統的云邊界之外所涉及的一些架構和權衡。 分布式分析如何增值 簡單的分析包括數據規約、關聯和求平均值,結果是輸出一串比輸入數據小得多的數據。例如,一座大樓的淡水供應系統。為了優化水泵和監測消耗,了解系統中各點的壓力和流量可能很有價值。這會涉及到分布在輸配管道周圍的壓力和流量傳感器陣列。軟件定期詢問傳感器,調整泵的設置,并為大樓管理人員生成用水報告。但是,傳感器的原始讀數可能具有誤導性—例如,沖洗固定裝置時的瞬時壓降。分析算法可以對指定傳感器一段時間內的讀數求平均值,并結合和關聯多個傳感器的讀數,以生成更準確、有用的管道狀況圖。所有這些讀數都可以發送到位于云端的分析系統,但如果傳感器自己做一些平均計算,讓本地邊緣計算機進行關聯和報告,這將是一個更高效的架構。這就是分布式分析,可以改善許多分析系統的效率、準確性和成本。 當采用人工智能/機器學習 (AI/ML) 技術時,分析會變得更加復雜。人工智能/機器學習通常分為兩個階段: · 一個是建模階段。在這個階段,大量的數據被提取出來,為AI/ML系統生成一個模型 · 一個是推斷階段。在這個階段,將模型應用于系統中的數據流,以生成期望的結果(通常是實時的) 在當今的系統中,這些模型幾乎總是建在大型服務器場或云端,通常是離線部署。然后,將生成的AI/ML模型打包并發送到不同的系統,這些系統使用實時數據運行模型的推斷階段,生成所需的結果。推斷階段可以在云端運行,但最近一直在向邊緣轉移,以改善延遲、網絡帶寬、可靠性和安全性。在決定每個階段使用哪個級別的計算資源時,需要認真考慮各個權衡因素。 AI/ML的推斷階段 AI/ML的推斷階段相對容易分布在多個同級處理器上,或者沿處理層的層次結構上下分布。如果模型經過預先計算,那么AI/ML算法使用的數據就可以在多個處理器之間進行劃分且并行計算。在多個同級處理器之間劃分工作負載帶來了容量、性能和規模優勢,因為隨著工作負載的增加,可以調動更多的計算資源去承擔。它還可以提高系統的可靠性,因為如果一個處理器出現故障,鄰近的處理器仍然可以完成工作。推斷操作也可以在一個層次結構的多個層次之間進行劃分,也許算法的不同部分會在處理器的不同層次上運行。這讓AI/ML算法能夠以合乎邏輯的方式進行劃分,允許層次結構的每一級執行最高效的算法子集。 例如,在視頻分析AI/ML系統中,攝像頭中的智能功能可以執行自適應對比度增強,將這些數據交給邊緣計算機執行特征提取,將其發送到鄰近的數據中心進行對象識別,最后,云端可以執行高級功能,如威脅檢測或熱圖生成。這可以是一種高效的分區。 AI/ML算法的學習階段 對AI/ML算法的學習階段進行分布難度更大。問題是上下文的大小。為了準備模型,AI/ML系統需要大批量的訓練數據,并用各種復雜的學習階段算法對其進行消化,從而生成一個在推斷階段相對容易執行的模型。如果在一個給定的計算節點上只有一部分訓練數據可用,算法在推廣模型時會遇到困難。這就是為何訓練通常在云端進行。在云端,內存和存儲空間幾乎是無限的。但是,某些場景需要將訓練算法分布在多個同級計算節點上,或者在云-到邊緣的層次結構中上下分布。特別是,邊緣學習能夠從附近的傳感器收集大量的訓練數據,并在沒有云參與的情況下利用數據,這樣可以改善延遲、可靠性、安全性和網絡帶寬。為了解決這些挑戰,目前正在開發先進的分布式學習算法。 結論 AI/ML是幾乎所有電子系統未來必須具備的重要能力。這些系統的推斷和訓練能力如何在計算資源的層次結構中進行劃分?存在哪些選項?了解這些選項是我們未來成功的關鍵。 來源: 作者:CHARLES C.BYERS |