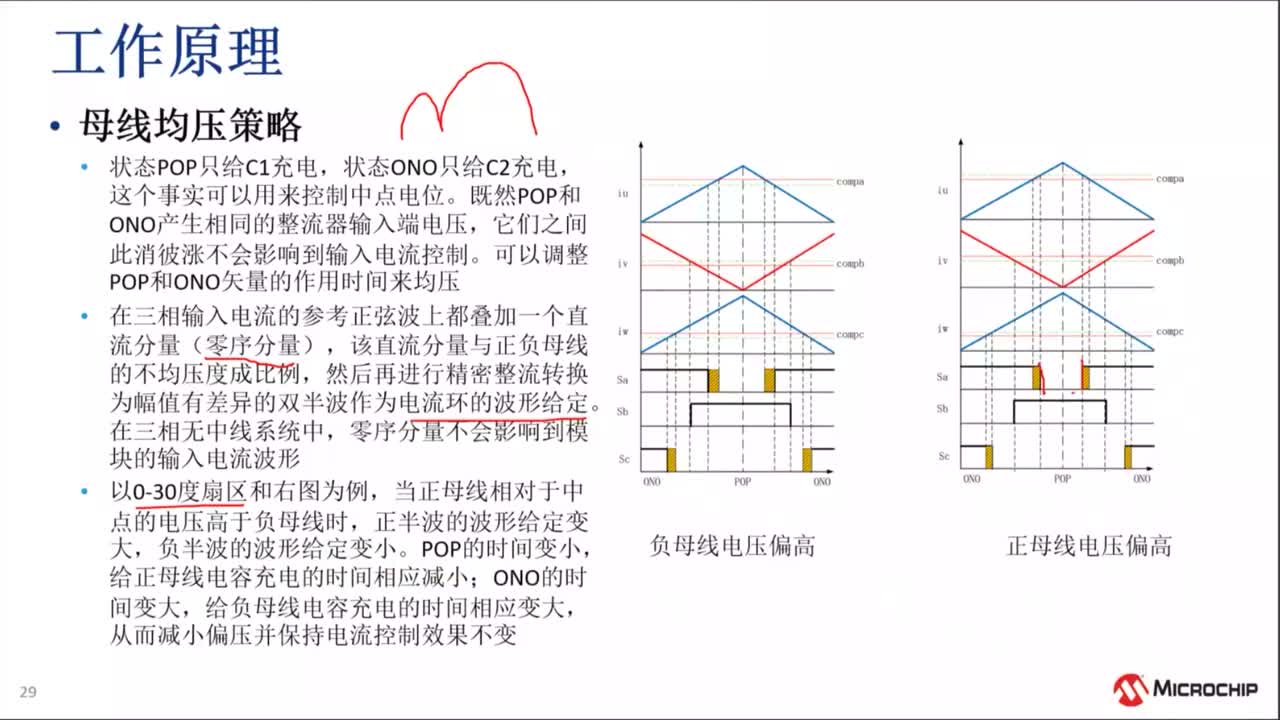
|
XScale是一款具有高性能、低功耗特性的ARM兼容嵌入式微處理器架構。XScale引入了多種硬件特性提高其處理能力,但也給應用程序的優化帶來了困難。本文介紹XScale體系結構的特點,從開發工具選擇、系統設計和編程開發等多個角度討論對XScale應用程序進行優化的策略和技術。 XScale體系結構是采用Intel Pentium技術實現的ARM兼容的嵌入式微處理器架構,并對ARM體系結構進行了增強,具有業界領先的高性能和低功耗特性被廣泛應用于消費電子、無線通信、多媒體和網絡交換等嵌入式應用領域。XScale引入了一系列高性能微處理器的設計技術,總體性能顯著地超出同主頻的ARM微處理器。然而,由于受功耗、成本和體積等因素的制約,嵌入式微處理器的處理能力與桌面系統相比仍存在較大差距。通常需要對嵌入式應用程序進行性能優化,以滿足嵌入式應用的性能需求。 業界對嵌入式系統的性能優化進行了很多研究與實踐。文獻為XScale優化編譯器的設計提供了多種優化技術,也可用于一些應用程序的手工優化;文獻從應用程序編程的角度討論了ARM嵌入式系統軟件設計優化技術;文獻討論了提高C/C++嵌入式應用程序性能的一些技巧,其中多數技術可以由優化編譯器中實現。 本文在總結XScale優化編譯器設計和XScale嵌入式系統設計開發工作的基礎上,從系統設計、開發工具選擇、編譯優化和編程開發等角度討論和提出了XScale應用程序的優化策略和技術。 1 XScale體系結構 XScale微架構引入了Pentium處理器工藝和系統結構技術,實現了Pentium微處理器體系結構的一系列高性能技術,達到了高性能、低功耗和小體積等嵌入式系統要求的特性。 (1)超流水線 Xscale的超流水線(SuperPipeline)技術,如圖1所示,由整數處理(integer)、乘加(MAC)和存儲(memory)3條流水線組成。3條流水線的長度是6到9段,前4到5段共享,后面分支部分并行工作可有效提高處理器性能。 (2)高主頻 采用Pentium工藝技術,XScale主頻可以超出普通ARM微處理器主頻數倍,在保持較低能量消耗的前提下,高達600MHz以上。如PXA27X的主頻可高達724MHz。 (3)存儲體系 XScale實現了一個高效的存儲器體系結構,為其超流水線的高效運行提供數據資源。XScale存儲體系功能主要包括32KB D-Cache、32KB I-Cache、2KB Mini Dcache、Fill Buffers、ending Buffers以及4.8GB/s帶寬的存儲總線,使處理器可以高效訪問存儲器。 (4)分支預測 XScale實現了基于統計分析的分支預測功能部件,減少由于分支轉移沖刷指令流水線的次數,也有效地提高了處理器的性能。 (5)指令集體系結構 針對ARM數據處理能力的不足,XScale對ARM的乘加邏輯進行了增強,增加了8條DSP指令。XScale處理器還可集成Flash閃存和無線MMX邏輯功能。這些特性有效地提高了XScale數據處理能力。帶有無線MMX的PXA27X在312MHz主頻運行處理多媒體應用時,其性能與520MHz ARM處理器相當。 (6)省去不常用的邏輯功能 為了節省處理器芯片體積和降低運行功耗,XScale體系結構沒有實現昂貴的浮點運算部件和除法部件。這些是嵌入式應用中不常用的運算。當需要這類運算時,可以通過軟件方法實現。 XScale復雜的體系結構給嵌入式應用程序的優化帶來了更大的困難。 2 性能優化技術 XScale處理器性能的發揮很大程度上依賴于應用程序的優化技術。XScale嵌入式應用系統的性能優化可以下幾個方面考慮。 2.1 算法結構優化 實現某種應用功能通常可采用多種算法或方法,不同算法的復雜度和效率差別很大。選擇一種高效的算法或對算法進行優化,可以使應用程序獲得最大的優化性能。常用的優化技術有以下幾種。 (1)選擇高效算法 如果算法效率低下,再快的處理器也會顯得不夠有,而一個高效的算法卻可以彌補處理器性能的不足。 考慮從已排序好的n個元素a[0:n-1]中找出某一特定元素x。如果采用順序搜索方式,從a[0]到a[n-1]逐個比較這n個元素,需要O(n)次比較。而如果采用二分搜索方法,則僅需O(logn)次比較。當n為2 31時,前一算法平均需要比較2 31次,后一算法平均僅需比較31次。兩者所需時間相差達10 8倍。 (2)遞歸算法非遞歸化 采用遞歸過程實現算法具有結構清晰、程序簡練易讀、正確性容易證明的特點;但遞歸算法通常需要執行大量的過程調用,并在堆棧中保存所有返回過程的局部變量,效率往往較低。當應用程序存在性能問題時,使用循不迭代方法將遞歸算法轉換成非遞歸算法往往可以使程序性能提高數倍。文獻對八皇后問題和Fibonacci數列的遞歸算法與非遞歸算法進行了性能比較試驗,結果如表1所列。 表1 遞歸算法和非遞歸算法的性能對比 問題 遞歸算法時間/s 非遞歸算法時間/s 加速比/倍 八皇后問題(最大棧深度為12) 100 20 5 Fibonacci數列(n=40) 50 1 50 算法優化是首選的優化技術。 2.2 編譯優化 隨著編譯技術的成熟,很多編譯器都實現了較強的代碼優化功能,可在編譯過程中自動對應用程序進行優化,改進一些不合理的結構,生成效率較高的目標代碼。 多數編譯器都可基于數據流分析實現別名分析、常數拆疊、常數傳播、公共子表達式消除、冗余代碼和死碼刪除、循環不變量的移動、循環逆轉、循環展開、函數嵌入等與體系結構無關的優化。 GNU gcc、WindRiverdiab、Intl XScale Compiler等常見編譯器都針對XScale體系結構進行了優化設計,可以有效地利用XScale/ARM指令的條件執行、條件設置和操作數移位等功能,使一條指令完成多個操作,縮短指令序列的長度;減少跳轉指令的數目,減少沖刷流水線的次數;按照XScale超流水線要求,利用3地址指令、多字傳送指令、DSP乘加指令和MMX指令等,生成高效的指令序列,提高應用程序的性能。 一些優化編譯器可借用并行程序設計技術,進行相關性分析,獲得源程序的語義信息,采用軟件流水線、數據規劃、循環重構等技術,使應用程序呈現更好的局部性,提高Cache命中率,從而提高計算密集型應用程序的性能。對于矩陣計算等計算密集型程序,一些高性能優化編譯器生成的代碼可以高出普通編譯器產生的代碼十倍之多。 應用程序開發過程中應該充分利用編譯器的代碼優化功能,在編碼時將主要精力集中在業務邏輯算法流程的設計上,提高編程效率和代碼可讀性。 2.3 編程優化 編譯優化是靜態優化。優化編譯器可以自動完成程序段和代碼塊范圍內的優化問題,但編譯器很難獲取程序語義信息、算法流程和程序運行狀態信息。很多情況下也需要編譯人員以某種方式將程序運行狀態信息傳遞給編譯器,或進行手工優化。以下是常用的編譯優化技術。 (1)使用inline函數 多數編譯器支持inline關鍵字。如果一個函數被設計成一個inline函數,那么在調用它們的地方將會用函數體來替代函數調用語句,這樣將會徹底省去函數調用的開銷。使用inline的最大缺點是函數在被多處調用時,代碼量將增大。 (2)減少函數調用參數 根據ARM過程調用規范,4個以下的形參通過寄存器傳遞,第5個以上的形參通過存儲器棧傳遞。顯然,通過存儲器棧傳送參數的開銷較大。函數調用形參限制在4個以內,可以降低函數調用的開銷。 (3)在Switch是一種使用普通的編程技術。編譯器為之產生if-else-if嵌套代碼,并按照順序進行比較,發現匹配則跳到滿足條件的語句執行。編程時,根據發生的相對頻率排序,將最可能發生的情況放在第一位,最不可能的情況放在最后一位,可以提高Switch語句塊的執行速度。 實際上,程序中if條件的處理也有類似的特性。 (4)避免使用C++的昂貴功耗 C++在支持軟件工程、面向對象程序設計、結構化對C進行卓有成效的改進,但在代碼尺寸、執行速度等方面比C語言差一些。C++的類機制與C語言的結構差別不大,但C++的多重繼承、虛擬基類、模板和運行類型識別等特性對代碼尺寸和運行效率有負面影響。對這些功能要慎重使用,可以通過試驗測試其影響的大小。 (5)減少或避免執行耗時的操作 應用程序的主要執行時間通常花費在關鍵路徑代碼段或程序模塊,關鍵路徑程序模塊往往包含循環或嵌套循環。減少循環或內層循環中昂貴操作的執行頻率可以顯著地提高應用程序的效率。常見的耗時操作有:I/O操作、文件訪問、圖形界面操作和系統調用等。 表2列出了XScale常見的I/O處理、系統調用和文件訪問等昂貴操作的代價。 表2 XScale常見最昂貴操作的代碼 操作類型 代價(時鐘周期/個) sprintf 828 fprintf 540 fread 552 fwrite 864 write 216 Read 216 除法 112 atoi 596 對于文件訪問等操作,每次讀入和寫出一個較大的數據塊,或使用內存映射技術訪問文件,可以減少相關系統調用執行的次數,從而提高程序執行的性能。下面是一個使用這種優化技術的示例。 優化前代碼: int data_in,int data_out; int file_in,file_out; … for(;;){ read(file_in,data_in,1); data_out=decode(%26;amp;data_in); write(file_out,%26;amp;data_out,1); } 優化后代碼: int data_in[1024], int data_out[1024]; int file_in,file_out; … for(;;){ read(file_in,data_in,1024); } (6)用查表代替計算 在處理器資源緊張和存儲器資源相對富余的情況下,可以用犧牲存儲空間換取速度的方法。例如需要頻繁計算正弦和余弦等函數數值時,可預先將函數值計算出來,置于內存,供以后查找。 2.4 高性能開發工具 應用程序的可執行代碼通常由編譯器編譯產生的目標代碼和鏈接程序從系統庫提取的庫例程兩部分組成。 選擇一種優化能力強的編譯器和開發工具可以生成更加高效的代碼。WindRiver Diab、GNU gcc、GNUpro和Intel XScale Compiler都針對XScale體系結構進行了優化。 嵌入式應用程序通常包含大量的系統函數調用。在XScale平臺上的測試結果表明:MediaBench的應用程序大約有50%的執行時間花費在系統庫函數,選用高效的系統運行庫(runtime library)也可使應用程序的運行效率獲得提升。如glibc庫的緩沖區的大小是newlib的數十倍,所以在處理輸入輸出操作方面具有更高的效率。 2.5 特定于XScale體系結構的優化 (1)避免除法 XScale沒有除法部件和整數除法指令,除法是由軟件實現的。軟件實現的除法效率很低,應該盡可能避免除法和計算余數等運算。有時可以將除法轉變為乘法。下面兩側是除法操作優化的示例。 ①用關系運算符兩邊乘除數消除除法操作 優化前:if((x/y)>z) 優化后:if(x>(y*z)) ②將除法轉換為乘常數和移位操作 優化前:v.x=(v1.x+v2.x+v3.x)/3 優化后:使用常數乘數0x5555轉換成 v.x=(int)(((_int64)(v1.x+v2.x+v3.x)* (_int64)0x55555)>>16); (2)避免浮點運算 XScale沒有實現浮點部件。浮點運算是通過系統庫實現的,代價很高,通常也應該避免,有時可以轉換成整數運算。包含浮點運算的庫例程有格式化輸入輸出(scanf/printf)等。XScale中常見浮點運算的代價如表3所列。 表3 XScale常見浮點運算的代價 運算類型 代價(時鐘周期/個) 加法+ 400 乘法* 400 除法/ 560 (3)使用GPP和IPP庫 XScale的很多硬件特性是針對多媒體嵌入式應用的特點而設計的,很難在編譯器中支持這些特性。為此,Intel公司對多媒體處理、圖形處理和數值運算的一些典型操作和算法進行了手工優化,設計成程序庫,分別稱為GPP/IPP庫。這些庫例程可以很好地發揮XScale硬件的計算潛能,達到很高的執行效率。用IPP庫實現除法和平方根的性能如圖2所示。 由圖2可以看出,使用IPP/GPP庫使相關操作的性能獲得大幅提升。 3 性能優化策略 應用程序的性能優化與縮短開發周期、軟件工程和OOP的目標之間通常存在矛質。嵌入式系統需要性能優,但性能優化需要人力物力投入,會增加開發時間,降低程序的可讀性,排斥使用新的開發工具和編程語言。而軟件工程的目標是使用高效的開發工具。編程語言和編程規范提高程序的可讀性、可靠性,縮短開發周期,降低項目成本。為此應該在二者之間尋找一種平衡。通常可以采取以下策略和原則; ①將算法結構優化作為首選優化技術,設計高效的應用程序流程和算法; ②根據功能、性能差異和投資預算選擇高效的編譯器、系統運行庫、圖形庫、中間件等; ③使用性能監測工具識別占主要執行時間的關鍵路徑程序模塊,采用一切優化手段對關鍵路徑代碼和程序模塊進行優化,挖掘應用程序性能; ④非關鍵路徑的流程控制代碼按照軟件工程的要求,采用高效率程序語言和開發工具實現,提高設計開發效率。使用編譯器進行優化。 結語 XScale體系結構按照嵌入式應用的要求,采用Pentium系列微處理器設計技術和工藝設計的一款性能突出的ARM兼容嵌入式微處理器。XScale體系結構引入了多種硬件特性增強處理器的性能,但也給應用程序優化帶來了挑戰。發揮XScale體系結構的性能,需要操作系統、編譯器、運行庫、連接程序和裝載程序等各層系統軟件的支持,需要在嵌入式項目的系統規范、開發工具選型、系統設計和編碼等多個階段考慮對應用程序進行優化。 |