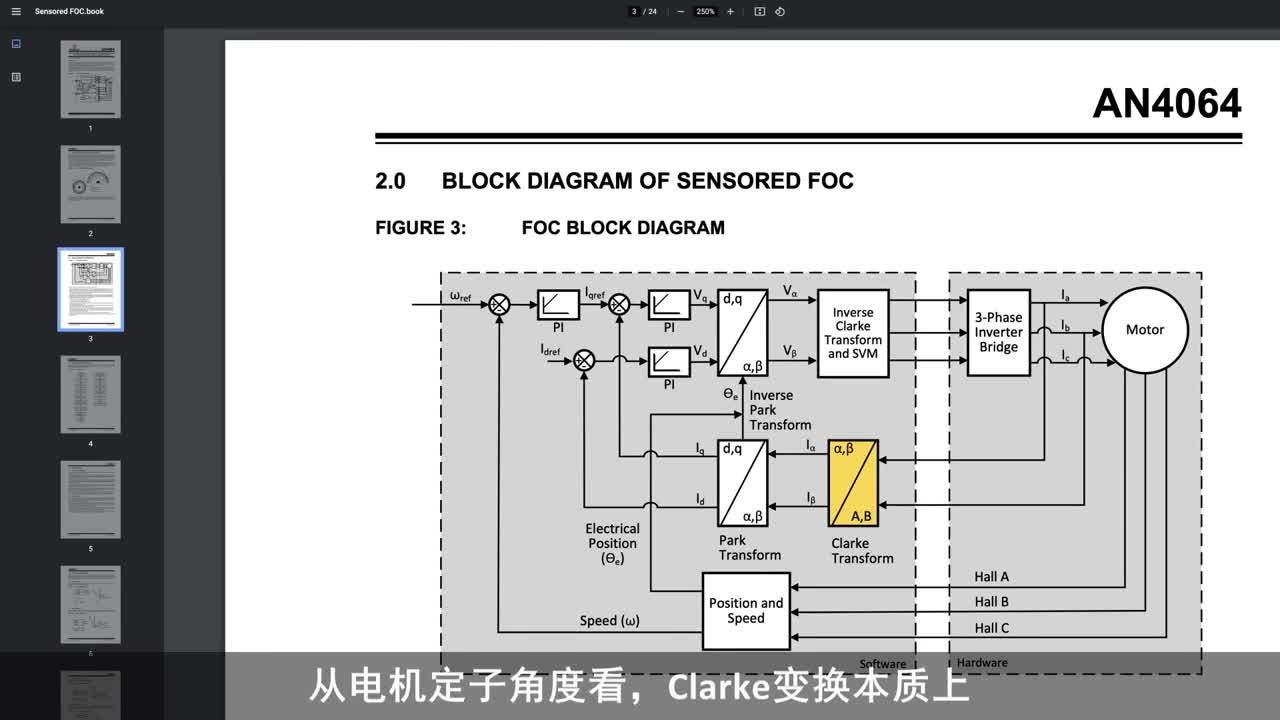
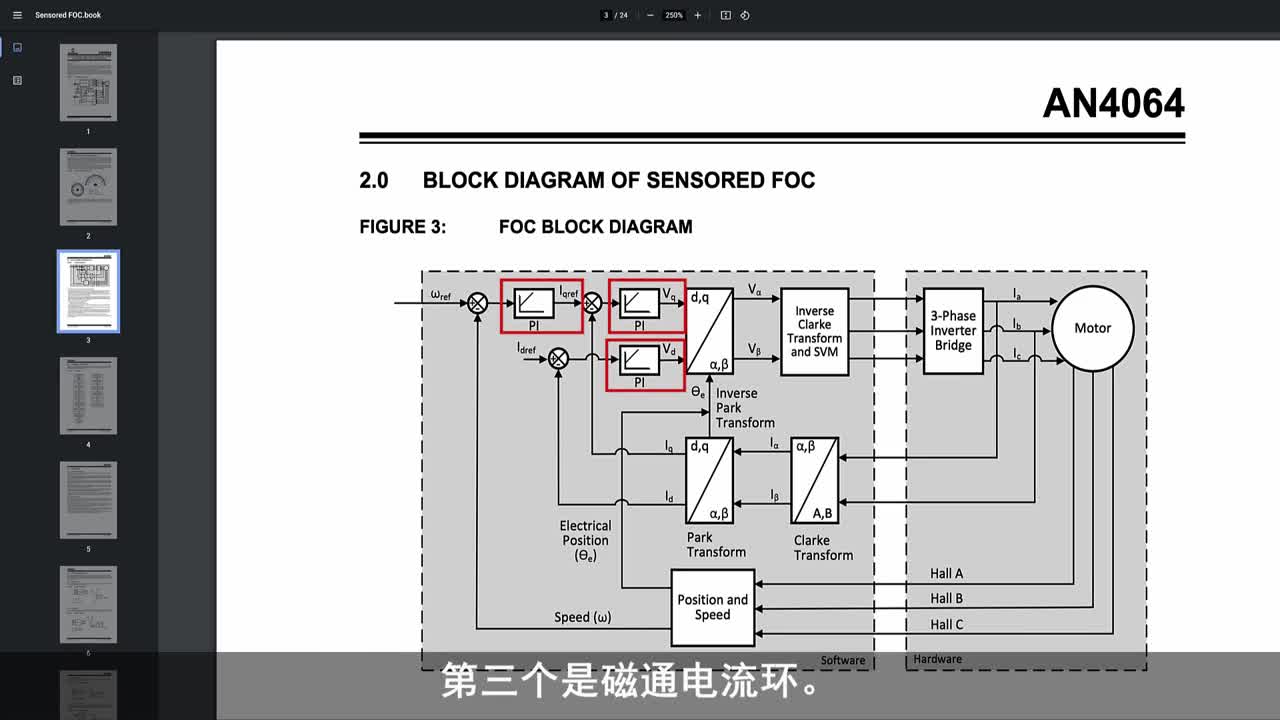
|
單向散列函數是密碼學中一種重要的工具,它可以將一個較長的位串映射成一個較短的位串,同時它的逆函數很難求解。許多安全技術中都會用到單向散列函數的這種特殊性質,比如數字簽名、密碼保護、消息鑒別等。鑒于單向散列函數在密碼系統中的重要地位,密碼學家們設計了各種各樣的安全散列函數。目前最常用的散列函數是NIST于1995年頒布的安全散列算法SHA-1。 SHA-1算法和之前的MD4、MD5等安全散列算法原理很接近,但是安全性更好。它可以通過一系列的迭代計算把任意長度的比特串壓縮成長度為160bit的位串。而且一般認為它的這個計算過程在密碼學意義上是單向的,也就是說很難找到兩個不同的位串可以壓縮成相同的160bit。到目前為止,還沒有對SHA-1有效的攻擊方法。 由于SHA-1算法的良好特性,它被廣泛使用在諸如電子商務這樣的現代安全領域,尤其是被大量應用于公鑰密碼系統的數字簽名中。目前幾乎所有相關密碼協議、標準或者系統中,都包括了SHA-1算法,其中比較著名的有SSL、IPSec和PKCS。在這些場合下,能否快速計算出消息的散列值直接影響到整個系統的處理能力。但是,由于SHA-1算法本身是一個很復雜的算法,計算量也較大,加上每次迭代都需要依賴上次的計算結果,因此不論是硬件還是軟件實現,計算速度都很有限,這大大限制了算法的適用場合。 本文提出一種新的硬件實現方法,通過改變迭代結構,達到縮短關鍵路徑的目的,進而提高SHA-1的計算速度。 SHA-1算法 算法描述 SHA-1算法能夠將任意長的輸入壓縮成160bit的輸出。但是,SHA-1算法中的基本迭代只能處理512bit的數據塊,因此為了處理任意長度的數據,首先需要將輸入的消息每512bit分成一塊,并且將最后一塊不足512bit的消息按一定規則補齊。(限于篇幅,SHA-1算法的詳細描述見文[1],下面是算法進一步的簡單描述。) 分塊之后就可以對每塊消息按下述方法依次進行處理。 1)在5個中間變量H0、H1、H2、H3和H4中置入特定初值。 2)對每塊消息依次執行步驟a)到e) a)將512bit的消息塊分成16個32bit的字W0,W1,…,W15; b)For t=16 to 79l etWt=S1(W t-3W t-8 W t-14 W t-16); c)LetA=H0,B=H1,C=H2,D=H3,E=H4; d)For t=0 to 79 do i)TEMP=S 5 (A)+f t(B,C,D)+E+Wt+Kt; ii)E=D;D=C;C=S30(B);B=A;A=TEMP; e)LetH0=H0+A,H1=H1+B,H2=H2+C,H3=H3+D,H4=H4+E。 所有消息塊處理完后得到的5個32bit變量H0到H4構成了160bit的數據,這就是SHA-1算法輸出的散列值。 算法中使用了一些簡單的邏輯函數和常數,其中函數ft()和常數Kt分別為 算法中S1(*)、S5(*)和S30(*)分別表示按位循環左移1bit、5bit和30bit。算子“∧”、“∨”、“?”和“+”分別表示按位“與”、按位“或”、按位“異或”以及32bit整數加法。 算法分析 從算法描述可以看出,SHA-1最核心的計算是一個計算5個中間變量的迭代: An=S5(A n-1)+f n(B n-1,C n-1,D n-1)+ E+Wn+Kn, Bn=A n-1, Cn=S30(B n-1), Dn=C n-1, En=D n-1. 在硬件實現中,5個變量在一個周期內同時由組合邏輯電路根據上次迭代的計算值產生,因此每次迭代所需要的時間是由最慢的計算過程決定。這樣一條最慢的計算路徑也就是所謂的關鍵路徑。如果完全按照SHA-1的原始算法進行硬件設計,那么很明顯的關鍵路徑是變量A的計算。在每次迭代過程中,計算變量A需要進行4次32bit的整數加法和若干組合邏輯。這些計算一共需要的時間也就是算法硬件實現的最短周期。正是因為變量A的計算比較復雜,造成SHA-1算法硬件實現的工作頻率難以提高。 因此,加快SHA-1硬件實現的計算速度關鍵就是改變迭代結構,從而縮短每次迭代過程的關鍵路徑。 硬件快速實現的新結構 觀察算法可發現,除了變量A以外,其他4個變量的計算都相當簡單。因此,如果將變量A的計算過程通過一定方式分解成若干并行的計算,那么就可以在不增加迭代次數的前提下,縮短整個計算的關鍵路徑。 出于這種目的,1997年A.Bosselaers等人對SHA-1算法的結構進行了分析,發現SHA-1算法的數據流圖可以分解成并行的7路數據處理,每路數據上一個周期只需一個基本操作:加法、“異或”或者循環移位。 在此關于SHA-1結構結論的基礎上,本文通過引入中間變量的方法,將計算的關鍵路徑分解成若干個較短的路徑,從而達到加速硬件計算的效果。考慮到硬件實現中32bit整數加法的延時遠遠大于循環移位和普通邏輯運算,所以分析關鍵路徑時只考慮加法的代價,而忽略其他邏輯運算的延時。 首先引入中間變量P n-1=fn(B n-1,C n-1,D n-1)+E n-1+Wn+Kn,那么可以得到An=S5(A n-1)+P n-1。也就是說,將第n次迭代的部分計算提前到第n-1次迭代中進行計算。變形后,第n次迭代中A的計算只需要進行一次32bit整數加法。 但是這種方式下,變量P的計算仍然需要依賴于同一次迭代中的其他變量,也就是說在一次迭代中需要在計算完其他變量后才能計算出P,這樣的話計算的關鍵路徑還是沒有縮短。所以還要充分利用A到E5個變量之間的相互關系 B n-1=A n-2, C n-1=S30(B n-2), D n-1=C n-2, E n-1=D n-2. 將P的計算變化為P n-1=f n(A n-2,S30(B n-2),C n-2)+D n-2+Wn+Kn。如此之后,第n-1輪的P值可以完全依賴于前一輪也就是第n-2輪的變量值計算而得。迭代計算的關鍵路徑就分裂成變量A和P兩路并行的計算。 類似的再引入其他中間變量,不斷的分解關鍵路徑,最終的迭代可變形為 An=S5(A n-1)+P n-1, Pn=f n+1(A n-1,S30(B n-1),C n-1)+Q n-1, Qn= C n-1+R n-1, Rn=W n+3+K n+3, Bn=A n-1, Cn=S30(B n-1). 可以發現通過引入中間變量,使得計算變量A的關鍵路徑分解成A、P、Q、R的4路并行計算,所需要的4次加法平均在4個周期內完成。這樣每次迭代過程中任何一個變量的計算最多只需要一次32bit整數加法和少量組合邏輯。在此基礎上,SHA-1算法可以通過如下方法來計算 1)將輸入的512bit消息分成16個字W0,W1, …,W15; 2)For t=16 to 79 let Wt=S1(W t-3 W t-8 W t-14 W t-16); 3)LetA=H0,B=H1,C=H2,D=H3; 4)LetP=f 0 (B,C,D)+E+W0+K0,Q=D+W1+K1,R=W2+K2; 5)Fort=0 to 79 do a)TEMP=S5(A)+P; b)P=f t+1(A,S30(B),C)+Q; c)Q=C+R; d)R=W t+3+K t+3; e)B=A;C=S30(B);A=TEMP; 6)LetH0=H0+A,H1=H1+B,H2=H2+C,H3=H3+S30(A76),H4=H4+S30(A75)。 雖然引入中間變量的計算后,每塊數據需要額外增加一個預計算的步驟4),但是因為關鍵路徑得以縮短,整體硬件實現的速度仍然會大大提高。 實現結果 使用Verilog硬件描述語言按本文提出的優化方法實現了SHA-1算法,并使用Synopsys Design Compiler在0.18Lm標準單元庫下綜合,得到表1中的結果。表1中還包括了文[6]的實現結果。文[6]同樣使用了0.18Lm工藝,但是實現SHA-1算法的方法仍然是傳統的直接計算ABCDE5個中間變量的方法。 表1ASIC實現結果比較 從前文的算法分析可以看出,傳統實現方法的關鍵路徑上有4次加法,如果把這4次加法按樹型組織,那么關鍵路徑的延時大約為3個32bit加法器的延時;通過本文方法改進后,關鍵路徑延時可以縮短為1個32bit加法器延時加上少量組合邏輯延時。因此理論上速度大約可以提高為傳統方法的2~3倍。從表1和使用傳統方法實現的文[6]對比可以發現,實現結果和理論分析完全一致。改進方法因為計算中引入了中間變量,所以面積比傳統方法要略大;同時為了計算中間變量的初值,每塊數據也需要多兩個周期的計算。但是因為關鍵路徑得以明顯縮短,整體的計算速度大大提高,吞吐量達到傳統方法的兩倍以上。 通過縮短關鍵路徑加速SHA-1計算的方法不僅適用于ASIC設計,而且一樣適用于基于FPGA的硬件設計。文[6,7]是目前常用的兩種SHA-1算法的商業IP核。使用本文提出的改進方法在和文[6,7]同樣的FPGA芯片上(XilinxVirtex2II系列XC2V50025)實現SHA-1算法。具體結果以及和文[6,7]結果的對比見表2。 表2FPGA實現結果比較 結論 針對有理分式擬合中的保證生成二端口網絡無源性的問題,本文提出了一種簡單且有效的局部補償方法,其主要思想在于:在生成網絡的Y參數矩陣的對角元素上加上(相當于并聯)一個RLC串聯的濾波回路,使得該回路可以以恰好補償原網絡違反無源性條件的頻率段,而盡量少的引入誤差。經過實驗表明,該方法能很好的達到預期的目的,在保證無源性條件的同時,能使引入的誤差限制在2%以內。 |