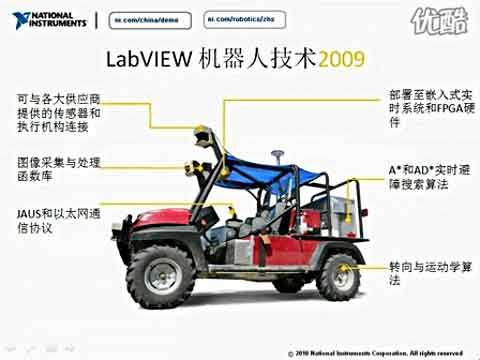
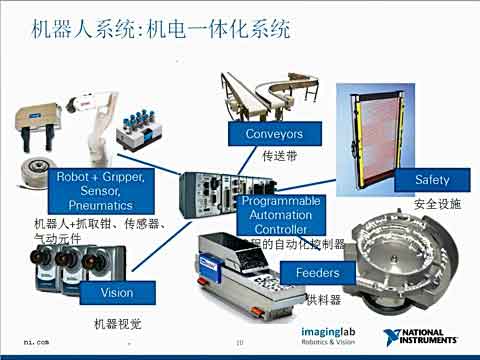
|
業內矚目的李世石與谷歌人工智能AlphaGo人機大戰已經賽罷3局,李世石第一局認輸之后,引起了全民關于人工智能的討論,很多人擔憂有一天人工智能將取代人類……此次人機大戰,無論最后的贏家是誰,以AlphaGo為代表的人工智能已經從實驗室逐步走向了商用道路,也開啟了未來的萬億級的大市場。其實很多技術已經在日常生活中和普通人有了關系。人工智能在諸如智能穿戴設備、無人機、基于大數據的業務分析等領域得到應用,節省了大量人工成本,機器人的時代已經到來,這已經是無可避免的歷程。今后機器人也將逐漸走進人類的生活中,甚至替代人類。雖然實體機器人短期無法普及到各個行業,但虛擬機器人接入簡單,使用方便,機動性強。一旦開始應用,便會像病毒一樣普及。。 智能機器人,是一種通過自然語言模擬人類進行對話的程序。通常運行在特定的軟件平臺上,主要功能是同用戶進行基本溝通并自動回復用戶有關產品或服務的問題,以實現降低企業客服運營成本、提升用戶體驗的目的。其應用場景通常為網站和手機終端。代表性的商用系統有:某新三板上市企業機器人"小x"、"風語者小懂機器人"等。 到底目前的智能機器人智能如何,優劣勢在哪里?日前,筆者通過對同樣以語義理解和人機交互為核心能力的兩家黑馬:風語者機器人"小懂"、某新三板上市企業機器人"小x"的技術進行對比,以讓讀者了解目前智能機器人發展的客觀現狀。 卷積神經網絡與深度神經網絡 "小x"選用當今最流行的深度神經網絡為主流技術,機器學習采用了有監督式學習模式(一些特別任務采用半自動化學習),知識庫構建方面采用一種特殊的結構將知識按照不同的屬性分類存儲在數據庫。風語者機器人小懂則采用更為先進的卷積神經網絡技術,機器學習方面大量應用了無需人工干預的無監督學習技術,知識庫方面則應用領域劃分的到最小單位,以特定領域的特定任務為核心構建高性能知識庫。卷積神經網絡相比深度神經網絡有何優勢?有監督學習和無監督學習?小懂、小x在知識庫構建有什么不同呢個?筆者對這三個問題,進行了更詳細的分析: 據羿歌信息科技所了解,深度神經網絡是現在各家人工智能企業最為流行的技術,大到微軟、google這樣的跨國大企業,小到創業中的圖靈、智齒無一不打出深度神經網絡的牌子。深度神經網絡也逐漸各家企業泛化,人工智能的各個行業無論是語音識別、還是圖形處理都號稱應用了這一技術。"小x"使用深度神經網絡也算跟上了時代的步伐,那么究竟什么是深度神經網絡,它的效果究竟如何呢?上個世紀50年代末,F·Rosenblatt設計制作了"感知機",它是一種多層的神經網絡。這項工作首次把人工神經網絡的研究從理論探討付諸工程實踐。當時,世界上許多實驗室仿效制作感知機,分別應用于文字識別、聲音識別、聲納信號識別以及學習記憶問題的研究。 神經網絡設計靈感來源于對人類大腦的一種模擬。神經元,也叫做神經細胞,是一種專門負責處理和傳輸信息的細胞。為了互相交流,它們會釋放出一種化學信號,或稱為神經遞質,利用突觸在細胞間傳遞信號。這些化學物質會立刻被相鄰的細胞接收,并轉換為電信號,也叫動作電位。動作電位會沿著神經元細長的軸突進行擴散。當它到達細胞另一頭時,電信號再次被轉化為化學信號,釋放到突觸,準備再次啟動整個過程。上述過程很像是計算機的信號傳遞,人工神經網絡正式模擬了這個過程,我們似乎在這里看到了創造人工大腦的希望。 然而,這次人工神經網絡的研究高潮未能持續很久,因為神經網絡計算量很大,以當時的計算機技術基礎模擬神經網絡是完全不可能的。1968年一本名為《感知機》的著作中指出線性感知機功能是有限的,它不能解決如異或這樣的基本問題,而且多層網絡還不能找到有效的計算方法,這些論點促使大批研究人員對于人工神經網絡的前景失去信心。60年代末期,人工神經網絡的研究進入了低潮。 但很多科學家并沒有放棄神經網絡的研究,1986年,Rumelhart、Hinton和Williams提出了多層的誤差反向傳播(ErrorBackPropagation,BP)算法,即BP算法。神經網絡經歷了從低谷再到高潮的階段,深度神經網絡概念也在此時誕生。其實,所謂的深度的神經網絡只是多加一些隱藏層,從下圖可知單層網絡只進行了一層計算,但多層網絡進行了多次計算最終得出結果。 深度網絡每層的作用是對上一層特征轉換,即以另一種編碼形式表示上一層的特征,同時應用上文提到的誤差反向傳播算法,以減少逐層傳遞的誤差。最后一層是一個傳統的分類器,大多數企業應用的是最大熵算法或支持向量機。雖然在本質上深度神經網絡看似與傳統神經網絡沒有區別,但是一方面由于硬件和具體算法水平的提高,另一方面由于反向傳播算法的應用,使得深度神經網絡技術大大優于傳統神經網絡。它首先被應用的到語音的識別中,此后逐漸在自然語言處理中發揮了作用。 與此同時,深度神經網絡的問題也很多暴露在算法工程師目前,主要有以下幾點: 1、如果訓練樣本足夠充分覆蓋未來的樣本,那么學到的多層權重可以很好的用來預測新的測試樣本。但是很多任務難以得到足夠多的標記樣本,這樣的話深度神經網絡的效果不僅比單層還差,甚至不如線性回歸或者決策樹的效果。 2、深度神經網絡的計算量太大,對5層以上的深度神經網絡計算速度已經達到了另人難以忍受的程度。 為了解決以上問題,小懂機器人提出了一個創造性的思路,將應用于圖形分析的卷積神經網絡技術應用于自然語言識別中。很多人會提出疑問了什么是卷積?卷積是通過兩個函數f和g生成第三個函數的一種數學算子,表征函數f與g經過翻轉和平移的重疊部分的面積。這種數學表示可能對于大多數人來說并不好理解。 我們舉一個圖形例子,假設是做一個人臉識別的任務,我們的要用卷積操作提取圖像的輪廓。我們首先把圖像表示成一個0-255的矩陣(黑色和白色之間有255種灰度)。我們用一個卷積8*8的卷積算子進行計算。計算方法:將中心點與其周圍的8個點依次比較,發現有一個差值大于某值n(n=100)的值時,就判斷其為輪廓線上的點并將之置為黑色;若其與周圍8個點的比較值都小于某值n時,則其不在輪廓線上,置白色。 剛才的操作就是卷積操作,我們發現通過卷積操作我們成功減少原圖的信息,可以在之后神經網絡計算中減少計算量。雖然卷積后的圖像信息比原圖的信息有所減少,但是對于特定任務,我們可以過濾不要的信息,從而提取我們所需要關注的特征。說到這里有人可能又會疑問了這和自然語言理解有什么關系。我們把可以一句話抽象成為一個矩陣。具體方法是把一句話的每個詞用一個詞向量表示,詞向量中的數值就是它的特征值。 有監督學習與無監督學習 上文看到,卷積網絡在計算速度和效果上還是明顯優于目前主流的深度神經網絡。下面再來談一下"小x"和"小懂"的機器學習方式。 機器學習方法是計算機利用已有的數據(經驗),得出了某種模型(如:遲到的規律),并利用此模型預測未來(如:是否遲到)的一種方法。我們首先將數據(語料)通過機器學習算法進行處理,這個過程在機器學習中叫做"訓練",處理的結果可以被我們用來對新的數據進行預測,這個結果一般稱之為"模型"。機器學習的目標是我們不告訴計算機怎么做,而是讓它(計算機)自己去學習怎樣做一些事情。機器學習的方式有兩種:有監督學習和無監督學習。 在有監督學習中,每個實例都是由一個輸入對象(通常為矢量)和一個期望的輸出值(也稱為監督信號)組成。監督學習算法是分析該訓練數據,并產生一個推斷的功能,其可以用于映射出新的實例。監督學習中在給予計算機學習樣本的同時,還告訴計算各個樣本所屬的類別。若所給的學習樣本不帶有類別信息,就是無監督學習。 再舉一個通俗的例子就是,假設兩個人去參加高考。一個人在平時練習的有習題集的答案,他所進行的就是有監督學習,另一個有習題集但是沒有答案,那么他所做的就是無監督的學習。這時候有人會提出對于機器學習的分類問題,沒有具體的標簽我們怎么進行分類呢?實際上,我們在對事物進行分類的時候,即使不知道具體分類方法,我們仍能夠將事物分成幾類。比如:一個幼兒,可以將玩具進行分類,如:各類的汽車、小動物、水果、家具。對于幼兒來講也許她并不知道某種具體的動物是什么,也不知道動物、汽車這些類屬概念,但是她依然可以對一堆玩具進行分類。因為每一類玩具有其特性,如:動物都有腿,汽車都有輪子。 我們舉一個自然語言處理中常見的詞典制作的過程,來對比兩種機器學習方式。假設我們制作一個人名的詞典,要標注出這個人物是科學家、企業家、政治家、還是歌星、影星。我們原始語料就是北京晚報。在沒有機器學習的模式下,這個詞典只有自己去建立。雇傭一群人,大家一起看報紙,把各個人名抄寫下來,之后寫上每個人物的屬性。這個方法需要耗費大量的人力成本,還有一問題就是你找到人需要有豐富的百科知識。比如:馮諾依曼,學習計算機的人都知道他是數學家、現代計算機的奠基人,不學這個學科的就未必知道了。 我們再來看一下有監督的學習是如何進行的,我們事先定義好人物的類別,比如分成10大類。我們再去定義每個類的特征,判斷科學家的規則: λ1(應用概率)X1:這個人名在科學文獻中出現。 λ2(應用概率)X2:文章出現"發明"一詞 λ3(應用概率)X3:與已有詞典中某個科學家名詞共同出現 。。。。。。 我們先要標注一部分的數據,去訓練每個前面的參數λ,通過這個標簽數據去學習出的規律,得出我們的模型(λ1,λ2….)。之后,之后再用這個模型去標注我們的北京晚報。這個過程顯然比上面純人工干活清松多了,但是這里面有幾個問題。 對于人物的分類你是否可以想全? 對于科學家這個分類如何進行下面的分類,即:再分成植物學家、天文學家。天文學家是否還有下面的分類。 科學家這個分類的特征模型(規則模型)是否合理。 帶著上面的問題我們再來看一下無監督的學習。與有監督學習不同,無監督學習不依賴預先定義的類或帶類標記的訓練實例。無監督學習是一種探索性的分析,在分類的過程中,人們不必事先給出一個分類的標準,聚類分析能夠從樣本數據出發,自動進行分類。當然我們這里要有定一些文本的特征。我們不必給出具體的規則,我們只需要給出這個人名所在的文本特征,如文本類型(不用指出具體類型),前后詞特征等。系統自動根據這些特征將科學家、企業家、政治家、藝術家等聚成不同的類,系統也可以繼續將科學家分成天文學家、物理學家、化學家等。 行業知識庫和任務知識庫 最后談一下知識庫的問題,"小x"機器人在知識存儲上的確有一些優勢。號稱可以通過業務知識分析,整理出業務知識公共屬性的抽象集合,如:業務介紹、業務資費、業務辦理方法、業務取消方法等屬性。我們不禁對其知識庫功效和構建方法產生幾點質疑。 1、這些知識在數據庫中能否形成推理,是否有足夠的規則,并且這些規則直接是有聯系,可以形成推理。我們對問題的推理往往基于假言三段論,即:P->Q;Q->R;P->R。.那么對于如此浩瀚知識網絡,我們能否有P和R之間的橋梁Q。 2、更為重要的一點是知識庫的構建需要耗費很多人力,同時需要大量的學科專家和語言專家的參與,建設周期長,對于小規模的數據效果很不好。 "小懂"機器人將知識的構建縮小的一個相對集中的任務上,如:根據用戶主訴病情推薦應做的檢查、智能寵物完成主人特定的任務。任務中包含的實體概念相對集中,實體與實體的關系也相對清晰。病情庫中的實體有:疾病、癥狀、時間、年齡、性別、檢查等。對于“小x"機器人號稱建立金融、交通幾大行業的知識庫,不知道它是真正的知識庫還是把數據庫包裝了一個華麗的概念。在大家都在吹噓行業知識庫的時候,我們姑且將"小懂"機器人的知識庫稱為任務知識庫,它針對一個特定任務而構建,能夠非常準確的完成用戶預定的任務。 綜合評價 反觀"小x"機器人,與"小懂"機器人相比,它則在走一條相對傳統技術的路線上,雖然對深度神經網已再度興起,但終究沒有改進時間復雜度高的痛點問題。"小x"機器人的機器學習算法、知識庫構方法需要進行人工標注、專家建庫等大量的人工參與,實際應用中需要針對客戶需求進行較長時間的二次研發。 可以說,"小懂"機器人是技術向商業轉化的成果,輸出的是產品。在很多技術方面,采用了獨創性的方法,解決了當今人工智能領域的很多痛點問題。相信在不久的將來,一個能夠讓人們與之無所不談的高"情商"智能機器人將走入我們的日常生活,成為我們的朋友、同事甚至是家人。讓我們拭目以待。共同迎來智能機器人發展的黃金時代。 |