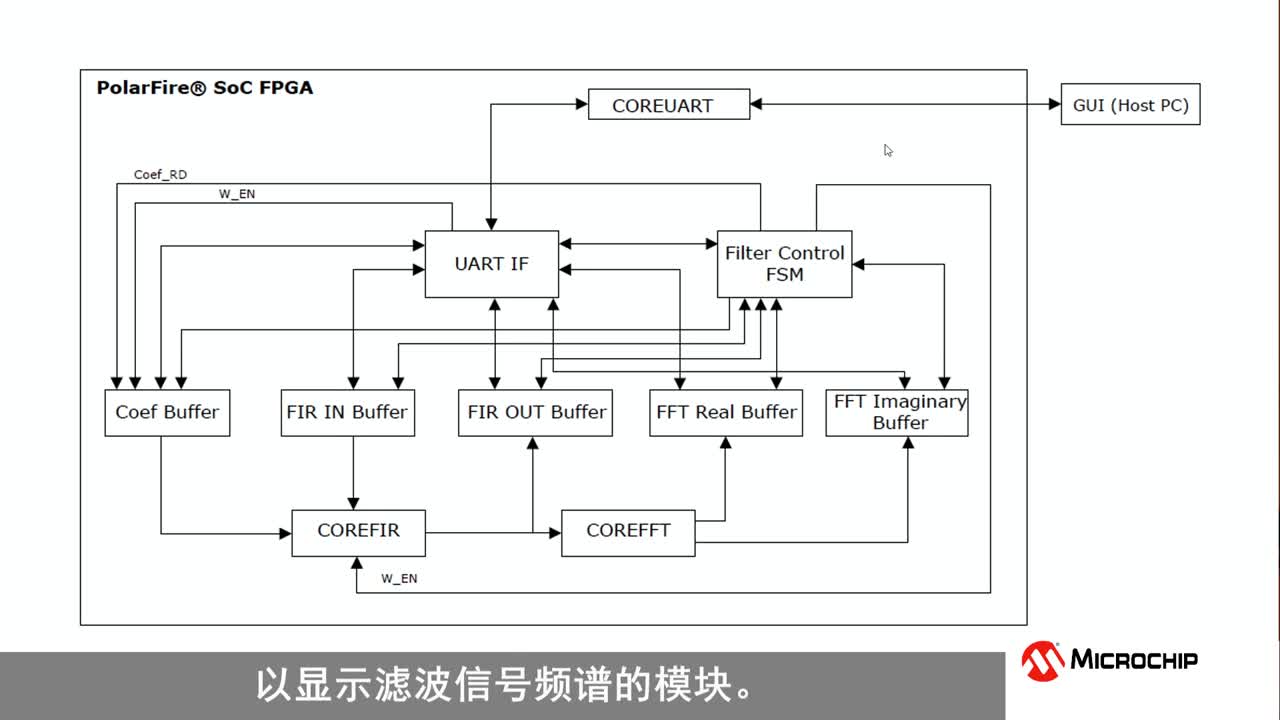
|
������꣬��ȌW(xu��)��(x��)�ɞ�Ӌ��C(j��)ҕ�X���Z���R�e����Ȼ�Z��̎�����P(gu��n)�I�I(l��ng)�������ʹ�õļ��g(sh��)�����I(y��)�����P(gu��n)ע��Ȼ������ȌW(xu��)��(x��)ģ����Ҫ�O������Ĕ�(sh��)��(j��)��Ӌ��������ֻ�и��õ�Ӳ�����ٗl�������ܝM��F(xi��n)�Д�(sh��)��(j��)��ģ��Ҏ(gu��)ģ�^�m(x��)�U(ku��)������F(xi��n)�еĽ�Q����ʹ�ÈD��̎���Ԫ��GPU����Ⱥ����ͨ��Ӌ��D��̎���Ԫ��GPGPU�������F(xi��n)���ɾ����T��У�FPGA���ṩ����һ��ֵ��̽���Ľ�Q�������՝u���е�FPGA�O(sh��)Ӌ����ʹ�䌦��ȌW(xu��)��(x��)�I(l��ng)��(j��ng)��ʹ�õ��ό�ܛ�������Ը���(qi��ng)��ʹ��FPGA�����מ�ģ�ʹ�Ͳ��������á�FPGA�ܘ�(g��u)�`�ʹ���о����܉����T��GPU�Ĺ̶��ܘ�(g��u)֮���M(j��n)��ģ�̓�(y��u)��̽����ͬ�r��F(xi��n)PGA�چ�λ�ܺ������ܸ���(qi��ng)���@����Ҏ(gu��)ģ����(w��)��������YԴ����Ƕ��ʽ��(y��ng)�õ��о��������P(gu��n)��Ҫ�����ď�Ӳ�����ٵ�ҕ�ǿ�����ȌW(xu��)��(x��)�cFPGA��ָ������Щڅ�ݺ̈́�(chu��ng)��ʹ���@Щ���g(sh��)�ƥ�䣬�����l(f��)��FPGA��Ύ�����ȌW(xu��)��(x��)�I(l��ng)��l(f��)չ��̽ӑ�� ���� �C(j��)���W(xu��)��(x��)���ճ�����Ӱ����h(yu��n)���oՓ���ھW(w��ng)վ���c(di��n)���Ի����]��(n��i)�ݡ��������֙C(j��)��ʹ���Z����ͨ���������沿�R�e���g(sh��)�����գ����õ���ij�N��ʽ���˹����ܼ��g(sh��)���@���˹����ܵ��³���Ҳ���S���㷨�O(sh��)Ӌ�������D(zhu��n)׃���^ȥ���ڔ�(sh��)��(j��)�ęC(j��)���W(xu��)��(x��)��������þ��w�I(l��ng)��Č��I(y��)֪�R���˹��ء����족��Ҫ�W(xu��)��(x��)�ġ���������Ӌ��C(j��)�Ĵ���ʾ����(sh��)��(j��)����(x��)�ýM��������ȡϵ�y(t��ng)���������tʹ��Ӌ��C(j��)ҕ�X���Z���R�e����Ȼ�Z��̎�����P(gu��n)�I�I(l��ng)��?q��)��F(xi��n)���ش������ͻ�ơ����@Щ��(sh��)��(j��)�(q��)�Ӽ��g(sh��)���о����Q����ȌW(xu��)��(x��)��������ܵ����g(sh��)��ɂ���ҪȺ�w���P(gu��n)ע��һ��ϣ��ʹ�ò�Ӗ(x��n)���@Щģ�͡��Ķ���(sh��)�F(xi��n)�O�����ܿ��΄�(w��)Ӌ����о��ߣ�����ϣ����F(xi��n)��(sh��)�����е���(y��ng)�Á������@Щģ�͵đ�(y��ng)�ÿƌW(xu��)�ҡ�Ȼ�������������R��һ�����Ɨl������Ӳ��������������ӏ�(qi��ng)���ſ��ܝM��U(ku��)��F(xi��n)�Д�(sh��)��(j��)���㷨Ҏ(gu��)ģ������ ������ȌW(xu��)��(x��)���f��ĿǰӲ��������Ҫ��ʹ�ÈD��̎���Ԫ��GPU����Ⱥ����ͨ��Ӌ��D��̎���Ԫ��GPGPU������Ȃ��y(t��ng)��ͨ��̎������GPP����GPU�ĺ���Ӌ������Ҫ����ׂ���(sh��)������Ҳ�������M(j��n)�в���Ӌ�㡣������NVIDIA CUDA��������������GPGPU����ƽ�_��������Ҫ����ȌW(xu��)��(x��)���߾�������M(j��n)��GPU���١�������_���Ͳ��г����O(sh��)Ӌ��(bi��o)��(zh��n)OpenCL���鮐��(g��u)Ӳ�����̵�����Թ��߂����P(gu��n)ע�������@Щ���ߵğ���Ҳ�ڸߝq���mȻ����ȌW(xu��)��(x��)�I(l��ng)���(n��i)��OpenCL�@�õ�֧�����^CUDA߀���dһ�I����OpenCL�Ѓ��(xi��ng)��(d��)�ص����ܡ����ȣ�OpenCL���_�l(f��)���_Դ�����M(f��i)����ͬ��CUDA��һ����(y��ng)�̵���������Σ�OpenCL֧��һϵ��Ӳ��������GPU��GPP���F(xi��n)���ɾ����T��У�FPGA���͔�(sh��)����̖̎������DSP���� ����GPU���㷨�����Ϗ�(qi��ng)�����ĸ����ߣ�F(xi��n)PGA�Ƿ�����֧�ֲ�ͬӲ�����@���Ȟ���Ҫ��FPGA�cGPU��֮ͬ̎����Ӳ�������`���FPGA���\(y��n)������W(xu��)��(x��)���P(gu��n)�I���ӳ������猦���Ӵ��ڵ�Ӌ�㣩�r����λ�ܺ���ͨ���ܱ�GPU�ṩ���õı��F(xi��n)�����^���O(sh��)��FPGA��Ҫ���wӲ����֪�R���S���о��ߺ͑�(y��ng)�ÿƌW(xu��)�Ҳ����߂䣬������ˣ�F(xi��n)PGA��(j��ng)��������һ�N�мҌ��ٵļܘ�(g��u)�������F(xi��n)PGA�����_ʼ���ð���OpenCL�ڃ�(n��i)��ܛ��������ģ�ͣ�ʹ��Խ��Խ�ܽ�(j��ng)����ܛ���_�l(f��)Ӗ(x��n)�����Ñ���A�� ������һϵ���O(sh��)Ӌ���ߵ��о��߶��ԣ��䌦���ߵĺY�x��(bi��o)��(zh��n)ͨ���c���Ƿ�߂��Ñ��Ѻõ�ܛ���_�l(f��)���ߡ��Ƿ�����`���������ģ���O(sh��)Ӌ�����Լ��Ƿ���Ѹ��Ӌ�㡢�Կs�p��ģ�͵�Ӗ(x��n)���r�g���P(gu��n)���S��FPGA��?y��n)�߳����O(sh��)Ӌ���ߵij��F(xi��n)��Խ��Խ������������ؘ�(g��u)����ʹ�ö��Ƽܘ�(g��u)�ɞ���ܣ�ͬ�r�߶ȵIJ���Ӌ�����������ָ���(zh��)���ٶȣ�F(xi��n)PGA������ȌW(xu��)��(x��)���о��ߎ�����̎�� ����(y��ng)�ÿƌW(xu��)�Ҷ��ԣ��M������ƵĹ����x��Ӳ�����x�����c(di��n)���������߆�λ�ܺĵ����ܣ��Ķ����Ҏ(gu��)ģ�\(y��n)�н��ͳɱ������ԣ�F(xi��n)PGA�{���λ�ܺĵď�(qi��ng)�����ܣ����Ϟ��ض���(y��ng)�ö��Ƽܘ�(g��u)��������������ȌW(xu��)��(x��)�đ�(y��ng)�ÿƌW(xu��)�����档 FPGA�ܝM�����ܱ���������һ���Ϻ�߉���x���Ŀ���FPGA����ȌW(xu��)��(x��)�ĬF(xi��n)��Լ�Ŀǰ�������a(b��)�����g���ϵļ��g(sh��)�l(f��)չ����ˣ�������������ҪĿ�ġ����ȣ�ָ����ȌW(xu��)��(x��)�I(l��ng)�����̽��ȫ��Ӳ������ƽ�_�ęC(j��)������FPGA��һ��������x����Σ����ճ�FPGA֧����ȌW(xu��)��(x��)�ĬF(xi��n)�ָ�����ڵ����ơ����FPGAӲ�����ٵ�δ����������P(gu��n)�I���h��������Q�����ȌW(xu��)��(x��)�����R�Ć��}�� FPGA ���y(t��ng)���f�����u��Ӳ��ƽ�_�ļ��ٕr����횿��]���`���Ժ�����֮�g�ę�(qu��n)�⡣һ���棬ͨ��̎������GPP�����ṩ�߶ȵ��`���Ժ������ԣ�����������ȱ��Ч�ʡ��@Щƽ�_���������ګ@ȡ�����Ե����ăr�����a(ch��n)�������m���ڶ�N��;���؏�(f��)ʹ�á���һ���棬���������·��ASIC�����ṩ�����ܣ������r�Dz����`�������a(ch��n)�y�ȸ����@Щ�·������ij�ض��đ�(y��ng)�ó��������a(ch��n)����r���F�Һĕr�� FPGA���@�ɂ��O��֮�g�����С�FPGA����һ�ͨ�õĿɾ���߉�O(sh��)�䣨PLD�������Һ����f����һ�N���������õļ����·����ˣ�F(xi��n)PGA�����ṩ�����·�����܃�(y��u)�ݣ��־߂�GPP���������õ��`���ԡ�FPGA�܉ε�ͨ�^ʹ���|�l(f��)����FF���팍(sh��)�F(xi��n)���߉����ͨ�^ʹ�ò��ұ���LUT���팍(sh��)�F(xi��n)�M��߉���F(xi��n)����FPGA߀����Ӳ���M���Ԍ�(sh��)�F(xi��n)һЩ���ù��ܣ�����ȫ̎������(n��i)�ˡ�ͨ�Ń�(n��i)�ˡ��\(y��n)���(n��i)�˺͉K��(n��i)�棨BRAM�������⣬Ŀǰ��FPGAڅ��څ����ϵ�y(t��ng)оƬ��SoC���O(sh��)Ӌ��������ARM�f(xi��)̎������FPGAͨ��λ��ͬһоƬ�С�Ŀǰ��FPGA�Ј���Xilinx����(d��o)��ռ��(j��)���^85�����Ј����~�����⣬F(xi��n)PGA��Ѹ��ȡ��ASIC�͑�(y��ng)�Ì��Ø�(bi��o)��(zh��n)�a(ch��n)Ʒ��ASSP���팍(sh��)�F(xi��n)�̶�����߉�� FPGA�Ј�Ҏ(gu��)ģ�A(y��)Ӌ��2016�ꌢ�_(d��)��100�|��Ԫ�� ������ȌW(xu��)��(x��)���ԣ�F(xi��n)PGA�ṩ�˃�(y��u)�ڂ��y(t��ng)GPP�����������@��������GPP��ܛ������Ĉ�(zh��)����ه�ڂ��y(t��ng)���T?�Z�����ܘ�(g��u)��ָ��͔�(sh��)��(j��)�惦���ⲿ�惦���У�����Ҫ�r��ȡ�����@�Ƅ��˾���ij��F(xi��n)�����p�p�˰��F���ⲿ�惦��������ԓ�ܘ�(g��u)��ƿ�i��̎�����ʹ惦��֮�g��ͨ�ţ��@��(y��n)��������GPP�����ܣ�����Ӱ���ȌW(xu��)��(x��)��(j��ng)����Ҫ�@ȡ�Ĵ惦��Ϣ���g(sh��)������^���ԣ�F(xi��n)PGA�Ŀɾ���߉ԭ�������ڌ�(sh��)�F(xi��n)��ͨ߉�����еĔ�(sh��)��(j��)�Ϳ���·����������ه���T?�Z�����Y(ji��)��(g��u)������Ҳ�܉����÷ֲ�ʽƬ�ϴ惦�����Լ����������ˮ�����У��@�cǰ������ȌW(xu��)��(x��)������Ȼ���ϡ��F(xi��n)��FPGA߀֧�ֲ��քӑB(t��i)�������ã���(d��ng)FPGA��һ���ֱ��������Õr��һ�����Կ�ʹ�á��@������Ҏ(gu��)ģ��ȌW(xu��)��(x��)ģʽ�a(ch��n)��Ӱ푣�F(xi��n)PGA�ĸ��ӿ��M(j��n)���������ã������_�y�����������M(j��n)�е�Ӌ�㡣�@�������ڟo���Ɇ�FPGA�ݼ{��ģ�ͣ�ͬ�r߀��ͨ�^�����g�Y(ji��)�������ڱ��ش惦�Խ��߰���ȫ��惦�xȡ�M(f��i)�á� ����Ҫ���ǣ������GPU��F(xi��n)PGA��Ӳ�������O(sh��)Ӌ��̽���ṩ����һ��ҕ�ǡ�GPU�������̶��ܘ�(g��u)���O(sh��)Ӌ����ѭܛ����(zh��)��ģ�ͣ������@����Ӌ���Ԫ�����Ԉ�(zh��)���΄�(w��)��Y(ji��)��(g��u)���ɴˣ�����ȌW(xu��)��(x��)���g(sh��)�_�l(f��)GPU��Ŀ��(bi��o)����ʹ�㷨�m��(y��ng)�@һģ�ͣ�Ӌ�㲢����ɡ��_����(sh��)��(j��)���ه���c���෴��F(xi��n)PGA�ܘ�(g��u)�Ǟ鑪(y��ng)�ó���?q��)��T���Ƶġ����_�l(f��)FPGA����ȌW(xu��)��(x��)���g(sh��)�r���^�ُ�(qi��ng)�{(di��o)ʹ�㷨�m��(y��ng)ij�̶�Ӌ��Y(ji��)��(g��u)���Ķ��������������ȥ̽���㷨����ă�(y��u)������Ҫ�ܶ���(f��)�s����Ӳ�����Ʋ����ļ��g(sh��)���y���ό�ܛ���Z���Ќ�(sh��)�F(xi��n)������FPGA��(zh��)�Ѕs�e������������Ȼ�����@�N�`�������Դ������g����λ�ͻ�·���r�g��ɱ��ģ�������Ҫͨ�^�O(sh��)Ӌѭ�h(hu��n)���ٵ������о��ˆT���f�@�������ǂ����}�� ���˾��g�r�g�⣬����ƫ���όӾ����Z�Ե��о��ˆT�͑�(y��ng)�ÿƌW(xu��)�ҁ��_�l(f��)FPGA�Ć��}�Ȟ��D�y���mȻ������ʹ��һ�Nܛ���Z�Գ�����ζ�������p�ɵ،W(xu��)��(x��)��һ�Nܛ���Z�ԣ�������Ӳ���Z�Է��g���܁��f�s����ˡ�ᘌ�FPGA��õ��Z����Verilog��VHDL�����߾���Ӳ�������Z�ԣ�HDL�����@Щ�Z�Ժ͂��y(t��ng)��ܛ���Z��֮�g����Ҫ�^(q��)�e�ǣ�HDLֻ�džμ�����Ӳ����������C�Z����ܛ���Z�Ԅt�������ָ����o���˽�Ӳ������Ĉ�(zh��)�м�(x��)��(ji��)����Ч������Ӳ����Ҫ����(sh��)�ֻ��O(sh��)Ӌ���·�Č��I(y��)֪�R���M��һЩ�ӵČ�(sh��)�F(xi��n)�Q���������o�ԄӺϳɹ���ȥ��(sh��)�F(xi��n)���������o���_(d��)����Ч���O(sh��)Ӌ����ˣ��о��ˆT�͑�(y��ng)�ÿƌW(xu��)�҃A�����x��ܛ���O(sh��)Ӌ�������ѽ�(j��ng)�dz����죬���д�������ͱ����ķ����߳���T��Ч�ʡ��@Щڅ��ʹ��FPGA�I(l��ng)��Ŀǰ������A�߶ȳ����O(sh��)Ӌ���ߡ� FPGA��ȌW(xu��)��(x��)�о���̱��� 1987VHDL�ɞ�IEEE��(bi��o)��(zh��n) 1992GANGLION�ɞ��ׂ�FPGA��(j��ng)�W(w��ng)�j(lu��)Ӳ����(sh��)�F(xi��n)�(xi��ng)Ŀ��Cox et al.�� 1994Synopsys�Ƴ���һ��FPGA�О�C�Ϸ��� 1996VIP�ɞ��ׂ�FPGA��CNN��(sh��)�F(xi��n)������Cloutier et al.�� 2005FPGA�Ј��rֵ�ӽ�20�|��Ԫ 2006�״�����BP�㷨��FPGA�ό�(sh��)�F(xi��n)5 GOPS��̎������ 2011Altera�Ƴ�OpenCL��֧��FPGA ���F(xi��n)��Ҏ(gu��)ģ�Ļ���FPGA��CNN�㷨�о���Farabet et al.�� 2016��ܛCatapult�(xi��ng)Ŀ�Ļ��A(ch��)�ϣ����F(xi��n)����FPGA�Ĕ�(sh��)��(j��)����CNN�㷨���٣�Ovtcharov et al.�� δ��չ�� ��ȌW(xu��)��(x��)��δ�������Ǿ�FPGA߀�ǿ��w���ԣ���Ҫȡ�Q�ڿɔU(ku��)չ�ԡ�Ҫ�@Щ���g(sh��)�ɹ���Qδ���Ć��}�����Ҫ��չ���܉�֧���w�����L�Ĕ�(sh��)��(j��)Ҏ(gu��)ģ�ͼܘ�(g��u)��FPGA���g(sh��)�����m��(y��ng)�@һڅ�ݣ���Ӳ�������������(n��i)�桢���ٵ������c(di��n)��(sh��)�������õĻ��B�l(f��)չ�����m��(y��ng)FPGA�������á�Ӣ�ؠ���ُ��Altera��IBM�cXilinx����������ʾ��FPGA�I(l��ng)���׃�δ��Ҳ���ܺܿ쿴��FPGA�c���ˑ�(y��ng)�ú͔�(sh��)��(j��)���đ�(y��ng)�õ����ϡ����⣬�㷨�O(sh��)Ӌ���߿��ܳ����M(j��n)һ�������w�(y��n)ܛ�����ķ���l(f��)չ���Ķ��������V���g(sh��)�������Ñ��� ������ȌW(xu��)��(x��)ܛ������ ����ȌW(xu��)��(x��)��õ�ܛ�������У���Щ�����ѽ�(j��ng)��֧��CUDA��ͬ�r���J(r��n)�R��֧��OpenCL�ı�Ҫ�ԡ��@��ʹ��FPGA������(sh��)�F(xi��n)��ȌW(xu��)��(x��)��Ŀ�ġ��mȻ��(j��)�҂���֪��Ŀǰ�]���κ���ȌW(xu��)��(x��)�������_��ʾ֧��FPGA�����^����ı����г�����Щ��������֧��OpenCL����l(f��)չ�� Caffe���ɲ�����ҕ�X�c�W(xu��)��(x��)�����_�l(f��)����GreenTea�(xi��ng)Ŀ��OpenCL�ṩ����ʽ֧�֡�Caffe����֧��OpenCL��AMD�汾�� Torch������Lua�Z�ԵĿƌW(xu��)Ӌ���ܣ�ʹ�÷����V�����(xi��ng)ĿCLTorch��OpenCL�ṩ����ʽ֧�֡� Theano��������������W(xu��)�_�l(f��)���������аl(f��)��gpuarray��ˌ�OpenCL�ṩ����ʽ֧�֡� DeepCL����Hugh Perkins�_�l(f��)��OpenCL�죬����Ӗ(x��n)�����e��(j��ng)�W(w��ng)�j(lu��)�� ���ڄ��M(j��n)����I(l��ng)��ϣ���x�ߵ��ˁ��f���҂��Ľ��h�Ǐ�Caffe�_ʼ����?y��n)���ʮ�ֳ��ã�֧���Ժã��Ñ����溆�Ρ�����Caffe��model zoo�죬Ҳ���������A(y��)��Ӗ(x��n)���õ�ģ���M(j��n)��ԇ�(y��n)�� ����Ӗ(x��n)�����ɶ� ���˻��S�Ԟ�Ӗ(x��n)���C(j��)���W(xu��)��(x��)�㷨���^������ȫ�Ԅӵģ���(sh��)�H����һЩ������(sh��)��Ҫ�{(di��o)����������ȌW(xu��)��(x��)�Ȟ���ˣ�ģ���څ���(sh��)���ϵď�(f��)�s�̶Ƚ�(j��ng)�����S���������ܵij�����(sh��)�M�ϡ������{(di��o)���ij�����(sh��)����Ӗ(x��n)�������Δ�(sh��)���W(xu��)��(x��)���ʡ����ݶȳߴ硢�[�؆�Ԫ��(sh��)�͌Ӕ�(sh��)�ȵȡ��{(di��o)���@Щ����(sh��)�����������п��ܵ�ģ���У����x���m����ij�����}��ģ�͡����y(t��ng)�����У�������(sh��)���O(sh��)��Ҫô���ս�(j��ng)�(y��n)��Ҫô����(j��)ϵ�y(t��ng)�W(w��ng)�����������Ч���S�C(j��)�������M(j��n)�С�����о����D(zhu��n)�����m��(y��ng)�Եķ������ó�����(sh��)�{(di��o)���ćLԇ�Y(ji��)������������(j��)�����У�ؐ�~˹��(y��u)������õķ����� �����úηN�����{(di��o)��������(sh��)��Ŀǰ���ù̶��ܘ�(g��u)��Ӗ(x��n)��������ij�N�̶��Ͼ�����ģ�͵Ŀ����ԣ�Ҳ�����f���҂����Sֻ�����еĽ�Q�����йܸQ��һ���֡��̶��ܘ�(g��u)ģ�̓�(n��i)�ij�����(sh��)�O(sh��)��̽��׃�ú����ף����磬�[�؆�Ԫ��(sh��)���Ӕ�(sh��)�ȣ�����ȥ̽����ͬģ���g�ą���(sh��)�O(sh��)��׃�ú��y�����磬ģ��e�IJ�ͬ������?y��n)����Ҫ��һ���������η���ij���̶��ܘ�(g��u)��ģ�́��M(j��n)��Ӗ(x��n)�����Ϳ���Ҫ�����L�r�g���෴��F(xi��n)PGA�`��ļܘ�(g��u)�����ܸ��m��������(y��u)����ͣ���?y��n)���FPGA�ܾ���һ����ȫ��ͬ��Ӳ���ܘ�(g��u)�����\(y��n)�Еr���١� �ͺ���Ӌ�㹝(ji��)�c(di��n)��Ⱥ ��ȌW(xu��)��(x��)ģ���������Եľ�������չ�����������Ǟ��ˏĔ�(sh��)��(j��)�аl(f��)�F(xi��n)��(f��)�s�ĸߌ�������߀�Ǟ锵(sh��)��(j��)���đ�(y��ng)���������ܣ���ȌW(xu��)��(x��)���g(sh��)��(j��ng)���ڶ(ji��)�c(di��n)Ӌ����A(ch��)�ܘ�(g��u)�g�M(j��n)����չ��Ŀǰ�Ľ�Q����ʹ�þ߂�Infiniband���B���g(sh��)��GPU��Ⱥ��MPI���Ķ���(sh��)�F(xi��n)�όӵIJ���Ӌ��������(ji��)�c(di��n)�g��(sh��)��(j��)�Ŀ��ق�ݔ��Ȼ������(d��ng)��Ҏ(gu��)ģ��(y��ng)�õ�ؓ(f��)�dԽ��Խ������ͬ��ʹ��FPGA���ܕ��Ǹ���(y��u)�ķ�����FPGA�Ŀɾ��������Sϵ�y(t��ng)����(j��)��(y��ng)�ú�ؓ(f��)�d�M(j��n)���������ã�ͬ�rFPGA���ܺıȸߣ���������һ����(sh��)��(j��)���Ľ��ͳɱ��� �Y(ji��)�Z ���GPU��GPP��F(xi��n)PGA�ڝM����ȌW(xu��)��(x��)��Ӳ���������ṩ�˾���������������������{����ˮ������Ӌ���������Ч���ܺģ�F(xi��n)PGA����һ�����ȌW(xu��)��(x��)��(y��ng)����չ�F(xi��n)GPU��GPP���]�еĪ�(d��)��(y��u)�ݡ�ͬ�r���㷨�O(sh��)Ӌ�����՝u���죬���FPGA���ɵ����õ���ȌW(xu��)��(x��)����ѳɞ���ܡ�δ����F(xi��n)PGA����Ч���m��(y��ng)��ȌW(xu��)��(x��)�İl(f��)չڅ�ݣ��ļܘ�(g��u)�ϴ_�����P(gu��n)��(y��ng)�ú��о��܉����Ɍ�(sh��)�F(xi��n)�� |