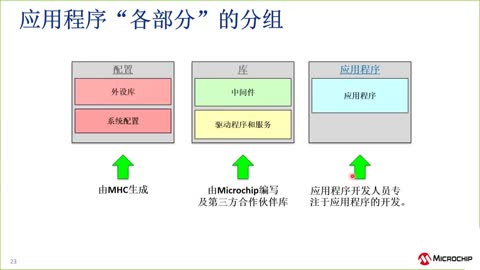
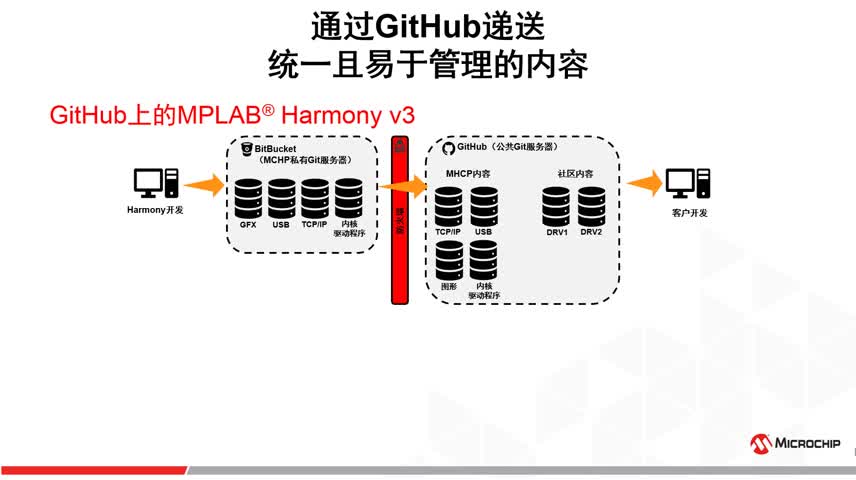
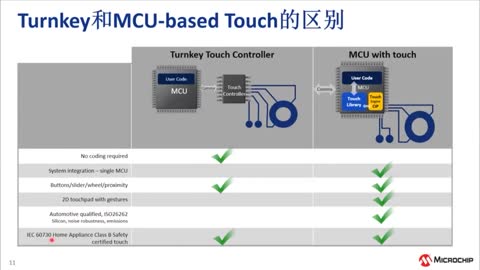
|
因為嵌入式應用領域的多樣性,每一個系統都具有各自的特點。在進行系統程序設計的時候,一定要進行具體分析,充分利用這些特點,揚長避短。 結合 ARM 架構本身的一些特點,在這里討論幾個常見的要點。 1.ARM 還是 Thumb? 在討論 ARM 還是 Thumb 之前,先說明 ARM 內核型號和 ARM 結構體系之間的區別和聯系。 如圖-1所示,ARM 的結構體系主要從版本 4 開始,發展到了現在的版本 6,結構體系的變化,對程序員而言最直接的影響就是指令集的變化。結構體系的演變意味著指令集的不斷擴展,值得慶幸的是 ARM 結構體系的發展一直保持了向上兼容,不會造成老版本程序在新結構體系上的不兼容。 
圖-1 ARM 結構體系和處理器家族的演變發展 在圖中的橫坐標上,顯示了每一個體系結構上都含有眾多的處理器型號,這是在同一體系結構下根據硬件配置和存儲器系統的不同而作的進一步細分。 需要注意的是通常我們用來區分 ARM 處理器家族的 ARM7、ARM9 或 ARM10,可能跨越不同的體系結構。 在ARM的體系結構版本4與5中, 還可以再細分出幾個小的擴展版本: V4T、V5TE和V5TEJ,其區別如圖-2中所示,這些后綴名也反映在各自擁有的處理器型號上面,可以進行直觀的分辨。V6 結構體系因為包含了以前版本的所有特性,所以不需要再進行分類。
圖-2 結構體系特征 上面介紹了整個 ARM 處理器家族的分布,主要是說明在一個特定的平臺上編寫程序的時候,一定要先弄清楚目標的特性和一些細微的差別,特別是需要具體優化特征的時候。 從 ARM 體系結構 V4T 以后,最大的變化是增加了一套 16 位的指令集——Thumb。到底在一個具體應用中要否采用 Thumb呢?首先我們來分析一下 ARM和 Thumb 各自的特點和優勢。先看下面一張性能分析圖:
圖-3 ARM 和 Thumb指令集的比較 圖中的縱坐標是測試向量 Dhrystone 在 20MHz 頻率下運行 1 秒鐘的結果, 其值越大表明性能越好;橫坐標是系統存儲器系統的數據總線寬度。結果表明: (a) 當系統具有32 位的數據總線寬度時,ARM 比 Thumb有更好的性能表現。 (b) 當系統的數據總線寬度小于32 位時,Thumb比 ARM 的性能更好。 由此可見, 并不是32位的ARM指令集性能一定強于16位的Thumb指令集,要具體情況具體分析。考察個中的原因,其實不難發現,因為當在一個 16 位存儲器系統里面取1 條 32位指令的時候,需要耗費2 個存儲器訪問周期;比之 32位的系統,其速度正好大概下降一半左右。而 16 位指令在 32 位存儲器系統或16 位存儲器系統里的表現基本相同。正是存儲器造成的系統瓶頸導致了這個有趣的差別。 除了在窄帶寬系統里面的性能優勢外, Thumb 指令的另外一個好處是代碼尺寸。同樣一段 C 代碼,用 Thumb 指令編譯的結果,其長度大約只占 ARM 編譯結果的 65%左右,可以明顯地節省存儲器空間。在大多數情況下,緊湊的代碼和窄帶寬的存儲器系統,還會帶來功耗上的優勢。 當然,如果在 32 位的系統上面,并且對系統性能要求很高的情況下,ARM是一個更好的選擇。畢竟在這種情況下,只有 32 位的指令集才能完全發揮 32位處理器的優勢來。 因此,選擇 ARM 還是 Thumb,需要從存儲器開銷和性能要求兩方面加以權衡考慮。 2.堆棧的分配 在圖-3 中,橫坐標上還有一種情況,就是 16 位的存儲器寬度,但是堆棧空間是 32 位的。這種情況下無論 ARM 還是 Thumb,其性能表現都比單純的 16 位存儲器系統情況下要好。這是因為 ARM 和 Thumb 其指令集雖然分 32 位和 16位,但是堆棧全部是采用32 位的。因此在 16 位堆棧和 32 位堆棧的不同環境下,其性能當然都會相差很多。這種差別還跟具體的應用程序密切相關,如果一個程 序堆棧的使用頻率相當高,則這種性能差異很大;反之則要小一些。 在基于 ARM 的系統中,堆棧不僅僅被用來進行諸如函數調用、中斷響應等時候的現場保護,還是程序局部變量和函數參數傳遞(如果大于4個)的存儲空間。所以出于系統整體性能考慮,要給堆棧分配相對訪問速度最快、數據寬度最大的存儲器空間。 一個嵌入式系統通常存在多種多樣的存儲器類型。設計的時候一定要先清楚每一種存儲器的訪問速度,地址分配和數據線寬度。然后根據不同程序和目標模塊對存儲器的不同要求進行合理分配,以期達到最佳配置狀態。 3.ROM 還是 RAM 在 0 地址處? 顯然當系統剛啟動的時候,0 地址處肯定是某種類型的 ROM,里面存儲了系統的啟動代碼。 但是很多靈活的系統設計中, 0 地址處的存儲器類型是可映射的。也就是說,可以通過軟件的方法,把別的存儲器(主要是快速的 RAM)分配以0 起始的地址。 這種做法的最主要目的之一是提高系統對中斷的反應速度。因為每一個中斷發生的時候,ARM 都需要從 0 地址處的中斷向量表開始其中斷響應流程,顯然把中斷向量表放在 RAM 里,比放在 ROM 里有更快的訪問速度。因此,如果系統提供了這一類的地址重映射功能,軟件設計者一定要加以利用。 下面是一個典型的經過 0 地址重映射之后的存儲空間分布圖,注意盡可能把速度要求最高的部分放置在系統里面訪問速度最快、帶寬最寬的 RAM 里面。
圖-4 系統存儲器分布的實例 4.存儲器地址重映射(memory remap) 存儲器地址重映射是當前很多先進控制器所具有的功能。在上一節中已經提到了 0 地址處存儲器重映射的例子,簡而言之,地址重映射就是可以通過軟件配置來改變一塊存儲器物理地址的一種機制或方法。 當一段程序對運行自己的存儲器進行重映射的時候,需要特別注意保證程序執行流程在重映射前后的承接關系。下面是一種典型的存儲器地址重映射情況:
圖-5 存儲器重映射舉例 1 系統上電后的缺省狀態是 0地址上放有 ROM,這塊 ROM 有兩個地址:從0起始和從0x10000 起始,里面存儲了初始化代碼。當進行地址 remap以后,從 0起始的地址被定向到了 RAM 上,ROM 則只保留有唯一的從 0x10000 起始的地址了。 如果存儲在 ROM 里的 Reset_Handler 一直在0 – 0x4000的地址上運行,則當執行完remap以后,下面的指令將從RAM 里預取,必然會導致程序執行流程的中斷。根據系統特點,可以用下面的辦法來解決這個問題: (1) 上電后系統從 0 地址開始自動執行,設計跳轉指令在 remap 發生前使 PC指針指向0x10000 開始的 ROM 地址中去,因為不同地址 指向的是同一塊ROM,所以程序能夠順利執行。 (2) 這時候 0 - 0x4000的地址空間空閑, 不被程序引用, 執行remap后把 RAM引進。因為程序一直在 0x10000 起始的 ROM 空間里 運行,remap 對運行流程沒有任何影響。 (3) 通過在 ROM 里運行的程序,對 RAM 進行相應的代碼和數據拷貝,完成應用程序運行的初始化。 下面是一段實現上述步驟的例程: ------------------------------------------------------------------------------------------------------- ENTRY ;啟動時,從 0 開始,設法跳轉到“真”的ROM 地址(0x10000 開始的空間里) LDR pc, =start ;insert vector table here … Start ;Begin of Reset_Handler ; 進行 remap設置 LDR r1, =Ctrl_reg ;假定控制 remap的寄存器 LDR r0, [r1] ORR r0, r0, #Remap_bit ;假定對控制寄存器進行 remap設置 STR r0, [r1] ;接下去可以進行從 ROM 到 RAM 的代碼和數據拷貝 ------------------------------------------------------------------------------------------------------- 除此之外,還有另外一種常見的remap方式,如下圖:
圖-6 存儲器重映射舉例 2 原來 RAM 和 ROM 各有自己的地址, 進行重映射以后 RAM 和 ROM 的地址都發生了變化,這種情況下,可以采用以下的方案: (1) 上電后,從 0 地址的 ROM 開始往下執行。 (2) 根據映射前的地址,對 RAM 進行必要的代碼和數據拷貝。 (3) 拷貝完成后,進行 remap操作。 (4) 因為 RAM 在 remap 前準備好了內容,使得 PC 指針能繼續在 RAM 里取到正確的指令。 不同的系統可能會有多種靈活的 remap方案,根據上面提到的兩個例子,可以總結出最根本的考慮是: 要使程序指針在 remap以后能繼續往下得到正確的指令。 5. 根據目標存儲器系統分散加載映像(scatterloading) Scatterloading 文件是 ARM 的工具鏈里面的一個特性,作為程序編譯過程中給連接器使用的一個參數,用來指定最終生成的目標映像文件運行時的分布狀態。如果用戶程序映像只是如圖7 所示的最簡狀態,所有的可執行代碼都集合放置在一起,那么可以不使用 Scatterloading 文件,直接用連接器的命令行選項就能夠完成設置: RO = 0x00000:表示映像的第一條指令開始地址; RW = 0x10000:表示變量區的起始地址,變量區一定要位于 RAM 區。
圖-7 簡單的映像分布舉例 但是一個復雜的系統可能會把映像分割成幾個部分。如圖 8,系統中存在多種類型的存儲器,不能的代碼部分根據執行性能優化的考慮分布與不同的地方。
圖-8 復雜的映像分布舉例 這時候不能通過簡單的 RO、RW 參數來完成實現上述配置,就要用到scatterloading 文件了。在 scatterloading文件里,可以給編譯出來的各個目標模塊指定運行地址,下面的例子是針對圖8 的。 FLASH 0x20000 0x8000 { FLASH 0x20000 0x8000 { init.o (Init, +First) * (+RO) } 32bitRAM 0x0000 { vectors.o (Vect, +First) handlers.o (+RO) } STACK 0x1000 UNINIT { stackheap.o (stack) } : : 16bitRAM 0x10000 { * (+RW,+ZI) } HEAP 0x15000 UNINIT { stackheap.o (heap) } } 關于 scatterloading文件的詳細語法,請參閱 ARM 公司的相關手冊。 引證文獻 1. 辛鑫.蒙建波.羅根 由 C到ARM匯編指令及程序優化 [期刊論文] -單片機與嵌入式系統應用2007(06) 2. 楊志強 嵌入式系統設計與發展 [期刊論文] -青海師范大學學報(自然科學版)2005(03) 3. 鄧海峰.余慧英.袁可風 一種嵌入式圖像處理平臺的設計與實現 [期刊論文] -計算機應用2005(z1) 4. 劉志勇 基于ARM的無線視頻傳輸硬件系統的初步研究與開發 [學位論文] 碩士2005 5. 劉峰雷 ARM9在新一代元件參數分析儀中的應用 [學位論文] 碩士2005 6. 王雷 基于ARM微處理器的應用研究 [學位論文] 碩士2005 7. 韓冰 車流量檢測信號處理系統設計 [學位論文] 碩士2005 作 者:ARM中國 費浙平 來 源:單片機與嵌入式系統應用2003(10) |