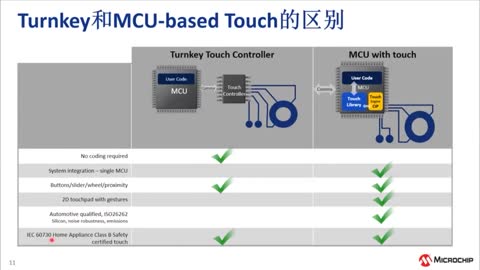
|
在計算機發展的整個70年期間,曾經出現了各種各樣的分立 和嵌入式處理器種群,它們已經進化,并且有些種群已經逐漸消失。從這一進化中產生了許多新奇的設計。有些新奇的概念繼續生存,有些幾乎立即消亡,而一些概 念僅僅存活了短暫的時間就銷聲匿跡了,但是,繼承他們基因的技術在后續的種群中再次出現。 本系列深度分析文章將調查13種不成功的處理器種群。這些文章探索了造成每一個處理器種群死亡的主要設計錯誤。每一個主要設計錯誤還用一個或幾 個例子來闡述。然而,隨著技術使得許多老的概念煥發新生、重塑輝煌并再次成為新概念而獲得無止境的重復利用,也許不知什么時候,勇猛的探索者/設計師將接 下來遇見這些處理器種群當中的哪一個呢?這些種群可能被當成是恐龍:許多基于這些概念的處理器曾經就是它們那個時代的優勢種群,或者,已經曾經大放光芒并 極其繁榮而引起了大量的關注。正是因為不斷進化的世界造成了我們的處理器種群的必然演化甚至滅絕,但這并不意味著一個處理器種群在它存在的鼎盛時期不能合 理地適應世界。 錯誤1:設計高水平的計算機指令集架構以支持特殊的語言或語言域(Myopisaur)。 從最早的計算時代起,人們不斷推動在抽象級解決編程問題,從接線板編程、撥動開關輸入、機器語言輸入、匯編語言到整個一大群“高級”編程語言(HLL),從上世紀50年代的Fortran和Cobol,乃至上下半葉研究出來的幾百或上千種編程語言。 HLL一被開發出來,人們就開始擔心用于捕獲編程問題的答案HLL描述與被在目標機上執行的由HLL編譯器產生的實際指令之間的語義差異。每一 種編譯器常常產生不好的結果—有時候非常糟糕。即使現在,盡管編譯器的開發經歷了50多年,但是,對于許多算法來說,最高技能的人類匯編語言編碼員所獲得 的編譯結果的質量,要比由最佳的HLL編程器與最佳的可用最優化編譯器所產生的代碼高一個數量級(或一個數量級以上)。 計算機研究人員和商用計算機供應商不可避免地開始研究根據特殊的HLL或語言種群調節一種特殊處理器的可行性,以期把處理器的指令集與語言的要求更為緊密地匹配起來,并縮小語義差異。其理論就是以那些目標HLL編寫的程序應該在這些經調整的機器上更為高效地執行。 一系列不合適的努力 為了實現這一方法—出現在從主機、微型機、分立微處理器IC到嵌入式處理器內核—的幾十年經驗以及努力,已經再三地確定這種方法是一個重大架構 錯誤。的確,在Hennessy和Patterson關于計算機架構的開創性圖書中可以發現這是典型的“謬誤和缺陷”之一[HEN, p. 142]。 這一方法存在的基本問題是多方面的:盡管已經被調整為一種語言,但是,處理器可能(而且非常可能將)被用于運行于其它語言編寫的程序。經調整的處理器將—因其針對特定語言的調整—在運行采用這些其它HLL編寫的程序時效率比較低。 在較早時代,硬件資源很少被花費在極少被采用的指令的有效執行上—這是對昂貴的架構資本的一種劣質應用。 因一種HLL構造的一些非常特殊的應用,針對特定語言的指令可能終止執行,并且對于典型和最常見的應用是沒有用的。因此,對這種指令的硬件本質上是一種浪費。 語言演化。基于固定、針對特殊HLL硬件的計算機架構較之于語言本身趨向于在非常長的時間內維持不變,因為軟件比硬件更加易于變化。 針對特殊HLL的處理器的流行被目標HLL的普及而被無情地終結。在各種語言中的少數體驗造成一種處理器具有最少的市場訴求。 因此,這種架構方法的缺陷花了很長時間才顯現出來。從上世紀60年代至80年代中期,在RISC架構方法發源以前,基于復雜指令集計算機 (CISC)、針對特殊HLL的計算機架構激起了巨大的興趣。研究人員撰寫了幾百或上千的論文,關于這個課題的專題研討會和座談會相當流行,而各個公司根 據這一設計哲學向市場推出各種真實的機器。 E-mode意味著緩慢的模式 Burroughs公司的"E-mode"機可能是被設計為支持特殊語言的最著名的機器系列。這個系列包括從上世紀60年代初至90年代的 B5000/6000/7000 和A-series機(一些兼容的處理器仍然在供貨)1。這些機器被設計為直接執行Algol 60。這種計算機家族還具有許多其它重要的功能,包括基于堆棧的架構、非平存儲器的利用、無匯編語言、操作系統和專用的管理子系統采用與Algol 60的直接對話編寫、并且采用的是48比特的存儲字(加上標簽比特)。的確,在上世紀60年代和70年代期間,Burroughs幾乎成為了針對特殊 HLL的計算機設計方法的偶像。 在這個時期,這家公司生產了中等規模和小型的針對Cobol的主機(B2000/3000/4000),以及一種被用于B1700/1800機 的有趣的微碼架構,其中,包括一組可以被進出交換以匹配不同語言的解釋指令集組。正如關于B5000的最熱心評論所說,Burroughs“專注于采用較 高級的編程注釋以實際地排斥機器或匯編語言”[EAR]。 遺憾的是,Burroughs E-mode機因HLL機的若干缺點而受損。它們在標準科學和商務處理語言—FORTRAN和COBOL—上的表現肯定是缺乏活力的。后來,為這些機器構 建C編譯器以及把Unix引入它們的根本架構上的嘗試被證明是困難的,因架構的分層存儲結構沒有小的部分。要嘗試把針對特定HLL的指令集擴展至較低端的 機器(包括由Burroughs的接任者Unisys在1989年推出的一種單芯片實現—稱為單芯片A系列主機處理器(SCAMP) [UNI])需要大量的微碼。遺憾的是,Algol 60從未真正以流行的編程語言起飛。這毫無疑問減少了Burroughs機的普及程度。 注釋:關于E-mode機—[ORG73]、[CHU-CAR]和[CHU-DOR]—有幾篇參考文選可用,這里僅僅給出了其中幾篇。 如上所述,Burroughs以面向B2000/3000/ 4000計算機的COBOL語言繼續它的針對特殊HLL的設計哲學,它至少具有針對更為流行、鎖定商務的HLL的有點。 許多語言,同樣差的結果 針對特定HLL的處理器設計的 吸引力,還導致人們開發直接運行用APL [HAS]、Lisp [WHO]、Prolog [FAG]以及其它直接針對Basic、Fortran、Pascal、PL/I和Snobol [DIT80]編寫的程序的機器。的確,針對特定HLL的計算機架構設計方法所存在的問題導致人們在1980年[DIT80]對它們進行了深刻的反思,只 是在CISC工作站出現之前、以及后來在上世紀80年代中期RISC處理器和工作站出現之時。 從主機時代向著小型和微型計算機時代的遷移,見證了上述針對特定HLL的計算機架構設計方法以Burroughs B1700/1800獲得重復使用,它為若干語言提供了微碼指令集(COBOL、RPG以及其中的Fortran) [ORG77]和許多專用的工作站級機器。被設計來直接執行LISP的機器就是一個特別著名的例子(LISP機、Symbolics)。 分立微處理器時代也看到了若干針對特定HLL的微處理器架構,包括:被設計來運行Occam的Inmos Transputer;由貝爾實驗室設計的用于直接執行C程序的CRISP處理器[DIT87a, DIT87b];在所有這類微處理器當中,也許最為著名(或聲名狼藉)的就是英特爾公司的432,它被設計為運行以Ada語言編寫的程序[GEH]。 Transputer及其Occam描述了一種針對特定HLL的處理器的功能之一,有時候,它的開發者對于特殊的計算理論以信奉宗教般或準宗教般的熱愛投 入,從而以奴性的方式證明它自己對于一種編程語言的奉獻,并盡力進行實質努力以開發一種支持它的機器。 盡管Transputer編譯器后來形成為更加傳統的HLL,但是,Transputer是以Occam推出的,這是一種基于Tony Hoare的計算序列處理概念。Transputer就是特定為Occam構建的。Inmos的領導人Iann Barron是Occam的最高牧師。Transputer的歷史描述了前面所列出的針對HLL的架構所存在的問題之一。它的成功高度依賴于找到一個對 Occam有足夠興趣的市場,以購買為它而設計的處理器,或者,對Transputer有足夠的興趣以采納它作為與眾不同的語言。這聽起來很像一次宗教對 話。 英特爾公司的432被設計為執行Ada,Ada在更為一般的意義上說是面向對象的語言。英特爾公司的432可能代表針對特定HLL處理器的極端 情況,它對任何語言均無法實現足夠的性能,包括用來設計它的Ada語言。實際上,英特爾公司的432微處理器整個冗長的故事一直遭受設計錯誤的折磨。在 [GEH]中引證了一些設計錯誤,我們發現它們分別是: —Ada編譯器產生謬誤的指令; 因此,英特爾的432執行通用的基準比Vax 11/780要慢10~26倍,而比8MHz 8086要慢2~23倍。對于英特爾來說,幸運的是,x86處理器以及用于IBM PC的接任者的演化取得了成功,從而讓英特爾的432完全消失,它已經被當今大多數的計算從業者所遺忘。 Java: 最新注定要失敗的努力 針對特定處理器的最后劫掠一直就在當今的嵌入式時代,利用由Sun、ARM以及其它供應商設計的特殊硬件來執行Java(Sun公司的 picoJava處理器以及ARM公司的Jazelle處理器等等)。這些針對Java的處理器鼓動起一些興趣,但是,并未激發狂熱。在當代的嵌入式世界 中,設計工程師為了陳述Java應用,在傳統的高性能處理器以及即時(JIT)編譯上解釋Java已經被證明是更加引人興趣的路線。此外,在嵌入式處理器 性能上的持續改善常常證明對于在嵌入式產品中的許多Java應用來說是相當足夠的,這些應用主要是面向控制和用戶界面。如果針對特定語言的處理器路線通過 四個計算時代已經證明它自身就是最令人誤導的方法的話,對于那些希望利用硬件以超越通用目的處理器的方式加速語言、以及用那些語言編寫的應用程序的人來 說,有什么其它的選項是不受限制的? 要拋棄的第一個概念一定是“一切關于語言”這個概念。的確,對于數據處理加強的應用來說,它更多的“一切關于”計算以及通信內核和嵌入在程序中 的算法。如果一個應用程序涉及重復地執行大矢量的標量積,那么,對于不采用具有規模適當的硬件乘法器或者更好的乘法-累加器(MAC)單元的處理器來說, 不論采用Fortran、Ada、C、Java、Basic或是COBOL編寫的程序來執行這一應用,其速度均會很慢。如果對于所采用的語言來說,處理器 具有合適功能的單元和良好HLL編譯器(或解釋器),那么,以這些語言當中的任何一種表達的算法應該執行得相當快速,不論采用什么語言。 正是算法的特征—而不是語言的特征—被用于設計、修改或選擇正確的處理器。對于這一應用,你或者可以搜尋一種具有乘法器或MAC單元的處理器 (和或零開銷的循環)—DSP可能是良好的選擇,或者—甚至更好的—你可以采用指令集擴展以裁剪一個可配置的處理器內核,使之更為精確地滿足應用的性能和 通信要求。在這種意義上說,搜尋一種針對特定HLL的計算機架構現在可以由搜尋一種面向特定應用的指令集處理器(ASIP)來取代。 注釋*:本系列文章以“Processor Design: System-On-Chip Computing for ASICs and FPGAs, Jari Nurmi (editor), Springer, June 2007. ”一書的其中一章為基礎。 注釋1:作者之一Grant Martin為Burroughs工作。在這篇系列文章中一再采用E-mode機作為例子,可以被視為對令人感興趣的那個時代的有點懷舊和充滿深情的回憶。 參考文獻: [CHU] Yaohan Chu 編,High-Level Language Computer Architecture,Academic Press, 紐約, 1975 |