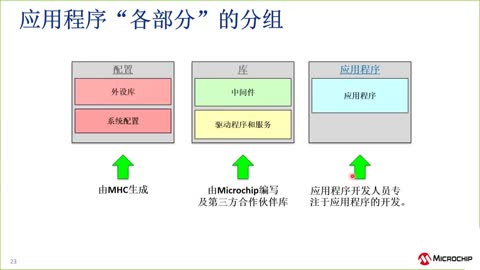
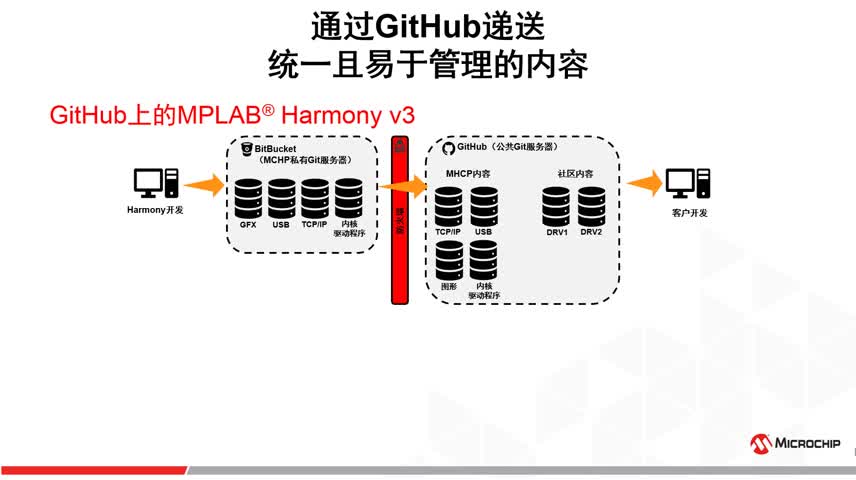
|
前些日子基于arm+uClinux開發了一個網絡監控系統,眼看項目馬上要做完了,終于松了一口氣,于是整理了一些筆記和心得想和大家針對這種開發模式進行一些探討,希望對各位有所幫助。 按照我的開發過程想分以下幾部分逐一介紹。 1.開發平臺的選擇和論證 2.開發環境的建立 3.一般程序的開發 4.Linux程序向ARM+uClinux平臺的移植 5.剩下的問題 希望諸位多多補充自己的想法,以利于大家共同提高。 1. 開發平臺的選擇和論證 一個項目拿到手,如何選擇開發平臺(主要是指CPU和操作系統以及開發環境和工具)應該說至關重要,有時這不光影響進度,產品質量,可維護性等一般問題,甚至涉及到方案的可實現性。本人結合自己的網絡監控系統簡單歸納了一些對平臺的考慮,還請各位補充。 從系統功能實現考慮: (1) 是否有片上外設,專用指令或配套的軟件模塊直接實現系統功能要求。 感 覺這一條對很多人的決策影響很大 (2) 價格 這一點應通過CPU提供的資源綜合考慮,它提供了多少有用的資源,多少沒用的資源(那可都是銀子呀!),還是那三個字,性價比,另一方面,是要抓主要矛盾,是不是有些特性是必須的,什么特性是用戶需求里的亮點(就靠這些亮點往上抬價),這時該花的就得花了。 (3) 功耗 本系統對CPU功耗要求不高,但對移動設備,這一點可是致命,而且這一點不是僅針對CPU,所有幾乎器件都要勒緊褲腰帶運行。 (4) 處理速度 這項不用多說,大家都明白重要性,但具體算起來可是一門學問,一方面是自己需要多快的速度,如果加上非實時操作系統這事就不好控制,余量還是大點穩妥,另一方面,CPU指令周期多少,有沒有流水,有沒有并行,什么體系結構,有沒有專用指令(看人家DSP多牛,干這事一絕),對外部存儲器和外設的存取速度等等,哪一個慢了都叫瓶頸。 (5) 需要的硬件支持(如外部存儲器,雙電源等) 這算是雜項,但會增加額外的價格,系統體積等,不容忽視。 從開發者的角度考慮: (1) 是否有足夠的技術支持包括demo版及原理圖,demo程序,操作系統和BSP,測試開發工具等。 (2) 自身條件;包括對項目開發周期的要求,開發人員對器件和開發模式的熟悉程度以及掌握的難易程度。 (3) 可用資源是否豐富(書籍,網絡等) 以上三點主要考慮迅速開發出穩定的系統。 (4) 系統的可繼承性,可移植性和可擴展性。 (5) 是否有現貨。 (6) 方案提供商的素質。(包括技術水平和服務意識)。 根據以上考慮選擇了s3c4510b(ARM7TDMI)+uClinux開發模式 (1) 以下是該平臺對我的系統的滿足情況:(和上面幾點對應) 本監控系統硬件部分主要要求以下部分: a.以太網接口 (s3c4510b自帶網絡控制器) b.串口 (自帶) c.與數據采集芯片的接口(8位數據線,小于8位地址總線)。(自帶) 本系統軟件部分主要要求以下部分: a. 硬件接口驅動程序 (uClinux提供串口和網絡控制器驅動) b. 網絡協議棧支持(uClinux提供TCPIP,UDP等的協議棧) c. 應用層程序(如果算上可以從linux移植的程序來看,那就太多了,我就用到了一個現成的) (2) 本應用系統不是那種批量的東西,對價格要求不苛刻,而且這款CPU最便宜可以到55左右,可以接受。 (3) 本應用系統有固定電源,功耗要求不高。當然,據說ARM在節省功耗上很有特點。 (4) 本應用系統速度方面要滿足兩方面:1。串口:115200bps 2。網絡速度 能到10Mbps就行,所以對系統速度要求也不高。這款ARM內部可以到50M。 (5) 系統對體積要求也不高,加片flash和RAM還是沒問題(到目前為止感覺我的系統真是無欲無求!) 從開發者的角度考慮: (1) 因為時間很緊(一個半月),所以支持越多越好。目前從開發商那里拿到了開發板,原理圖,uClinux,相應驅動,bootloader,拿來就可以用了。軟件硬件并行開發。(bootloader和網絡控制器驅動沒提供原碼,比較可惜:-( (2) 當時我對嵌入式系統的開發模式和ARM都是只有耳聞,linux接觸過一個月左右。現在想起來有些后怕。 (3) 網上的資源,非常多。 提供一些我常用的。 http://www.uclinux.org/ uClinux的大本營。 http://www.ucdot.org/ 里面有些技術文章非常不錯。 http://www.linuxdevices.com/ http://www.linuxeden.com/ 這是國產的linux站點。 uclinux-dev@uclinux.org 這是uClinux的郵件列表,回答問題的都是大牛,非常有幫助,記住把你的郵件設置成純文本格式。 申請是在: http://mailman.uclinux.org/mailman/listinfo/uclinux-dev web方式。 (4) 采用以上開發模式,軟件的可維護性,可移植性和可擴展性都不錯。 (5) 目前該CPU使用還是比較普遍,現貨沒問題。 (6) 方案提供商的素質嗎……..還算可以吧:-) 根據以上考慮和目前的開發情況,這套方案還是比較令人滿意。 今天先回家了,下回介紹具體開發步鄹吧。 2.開發環境的建立 先說兩句廢話為和我以前一樣對操作系統(尤其是嵌入式操作系統)迷惑的弟兄解釋些概念。因為總是有人在問是不是一定要用操作系統,我的CPU能不能移植操作系統,可以移植什么操作系統,有了操作系統可不可以運行某些程序。 從我的個人經歷來講,這其實就是許多硬件出身的弟兄對操作系統這個東西有神秘感(和我一年前一樣)。說白了,操作系統就是一段設計非常巧妙的程序,和你自己的程序從本質講沒有區別,于是,以上問題轉為,我是不是一定要用這段程序,我的CPU能不能運行這段程序,可以跑什么樣的程序。這個程序可以跑,調用這個程序接口的另一個程序能不能跑! 答案也就變得簡單,操作系統對任何一個CPU都不是必須的(對嵌入式系統更是如此),你可以自己編些程序在沒有操作系統的PC裸機上跑(BIOS就是這樣的),像玩C51一樣,(雖然奢侈的讓人有些心痛),或者移植UCOS到上面。另一方面,現代操作系統大多需要一些硬件的支持,(像保護模式的實現),反過來說,高端CPU中專門有針對支持操作系統的體系結構,這樣,許多操作系統的實現是挑剔硬件平臺的。其實其它程序也一樣,你編的程序使用的片上外設另一CPU上沒有,那這段程序就無法移植了。這就是話粗理不粗。書歸正傳,還是聊聊ARM+uClinux開發模式下開發環境的建立(其實下面說到的東西不僅限于這種硬件平臺和操作系統) 很久以前就在介紹嵌入式系統開發的書上見過“交叉編譯環境”這詞,當時覺得很玄,用了以后才知道,其實就是解決在誰的地盤上用誰的工具編誰的代碼問題。 編譯的最主要的工作就在將你的程序轉化成運行該程序的CPU所能識別的機器代碼,不同的CPU有相應的編譯器,另一方面。編譯器本身也是程序,當然也要在某一個CPU平臺上運行。于是交叉編譯的交叉點就在那個編譯器本身是CPU1上的一個程序,卻在為CPU2編譯代碼(整個一個吃里扒外!)。這么一想,以前用51和dsp的開發軟件(大部分都是IDE-集成開發環境)開發程序時,都算是交叉編譯啦。當然,假如在你的ARM系統上,操作系統已經正常運行,并且你的資源足夠多,你可以把PC機上運行的ARM編譯工具移植到ARM上,然后所有該系統的應用程序都直接在ARM系統上編譯,這就不算交叉編譯,但如果有條件這么作,程序的開發或者移植就方便多了,因為整個開發過程又回到在自己PC機上編應用程序的那種模式了,那就是在自己的地盤上用自己的編譯器編自己的應用程序。 與不使用操作系統的開發模式不同(此處的操作系統尤其指提供了專門的接口函數庫的操作系統,目前的UCOS就不算),在目標板(就是實現系統的板子)使用操作系統的開發模式下,交叉編譯環境中還需要該對應該操作系統的庫。比如uClinux提供的uClibc。此時,開發用的主機上不光要有目標板 CPU所需的編譯工具,還要有對應操作系統的庫,又因為一般庫文件還要在開發機上拿目標CPU的編譯器重新編譯一下,所以還要把操作系統的原碼也放到開發機上。(唉,跟目標板沒什么關系,卻要幫它背這么多東西,真是上輩子欠它的!!)。 雖然操作系統的接口庫至關重要,但大家似乎已經淡忘了它的存在。這些多是因為大家已經遠離了刀耕火種的年代(需要告訴編譯器需要的include路徑,lib路徑,以及lib的名稱),集成的編譯環境讓我們編譯鏈接的所有繁瑣工作化作對BUILD按鈕的瀟灑一擊。而且不論是windows環境,還是 linux環境,都有環境變量去記錄這些參數。。但嘗試將/usr/lib目錄改一個名字,你就會知道你不能無視他們的存在,因為操作系統的功能都是通過這些庫來交給應用層程序使用的。當然如果你的系統不依靠任何操作系統,像最原始的那種完全自己實現所有代碼,就只需要一個編譯工具,少了這些羅嗦事。 以上的東西一般時候是沒有必要仔細研究,但交叉環境下開發或移植比較大的程序時,你可能就需要了解編譯器,鏈接器等開發工具的幾乎所有重要參數。 我在開發時,主機完全使用的是linux,如果有條件,建議大家這樣作,linux的使用沒有想象的復雜(雖然我現在身邊還要放一本關于linux使用的書籍),而且開發程序可以先在主機上調通,然后用交叉編譯工具為目標系統重新編譯一遍,可以這樣做是因為主機是linux,目標系統跑 uClinux,兩個操作系統提供的應用程序接口幾乎是一樣的,所以程序幾乎不用修改。 在我的系統上,建立基本的開發環境過程如下。 1) 安裝gnu開發工具鏈(是GNU開發的針對ARM CPU的一組編譯開發程序(是linux程序)。包括arm-elf-gcc,arm-elf-ld等 (2) 將uClinux源代碼源代碼解壓到相應路徑下,按照編譯內核的步鄹編譯一遍(此時使用的編譯工具已經是上面提到的ARM編譯工具了,因為它要在ARM CPU上運行,另外,和編譯linux內核一樣,此時可以通過menuconfig來對內核提供的功能進行裁減 (3) 將庫(uClibc)解壓到相應路徑下,用以上工具編譯一遍。 這樣最基本的環境就算搭建好了。 以上工作對于做過的人來說比較簡單,這里介紹一下幫助沒有使用或剛開始使用這種開發模式的弟兄們理清一下思路。 3.一般應用程序的開發 因為目標板上用uClinux,它提供的程序接口和linux下的基本一致,不一致的部分主要在于uClinux 不支持MMU(應該說是uClinux是為不帶MMU的cpu定制的),最明顯的就是fork函數要用vfork函數替代,這也是編程時,感覺最不爽的一點(沒辦法,誰讓咱們的CPU有生理缺陷)。另一個不易覺察的差異在于uClinux提供的庫uClibc是經過裁減的。更適合于資源緊張的嵌入式系統(上回分解已經說了,應用程序很大一部分是在和庫函數打交道,而且大家最終是鏈在一起,所以庫函數大了,你的程序也小不了)。 于是基于這種開發模式的應用程序開發變成了linux下的程序開發。而且在實際中一般是編好了程序先在主機上拿主機平臺上的編譯器編譯并且調試一下(linux下的編譯器就是gcc了),當然前提是被調試的程序中需要的硬件條件主機具備,例如我的程序中有一段是針對串口的,于是先在主機編一個串口程序,調通以后拿目標板的編譯器重新編譯一下(如果看了上一章“交叉編譯環境”,這里就不會暈了),下載到目標板上運行,一般來說就可以直接用了。 以上也是為什么我認為開發嵌入式linux程序主機應該選用linux環境。對于以前沒用過linux的人來說(比如我),開發程序前應該花3,4天時間熟悉linux環境,尤其是它的編輯器,用慣集成編譯環境的人有時連編譯器和編輯器的概念都模糊了,所以一般是直接進入集成編譯環境,連寫帶編一氣呵成,殊不知有些集成編譯器提供的編輯器弱智的一塌胡涂,如果用熟了linux下的emacs,你就會發現他們之間的差距大概……要像我和蓋茨那么大吧。所以編程序時應該選一款優秀的編輯器,linux下,我當然選emacs,雖然剛看見它的感覺是外表丑陋,使用復雜。但只要多用多練,對提高效率很有幫助。(將你的程序用兩個編輯器完成,一半是用emacs的,一半是不用emacs的,看看效果:-) 對具體的linux編程我就不板門弄斧了,需要提個醒的是咱硬件出身的人作軟件應該養成良好的編程習慣,別讓作軟件的笑話咱。因為作了些網絡應用,所以介紹一些網絡編程時要用到的網站和書籍; < http://www.fanqiang.com/a4/b7/適合于網絡編程的入門。 還有IBM中國上關于linux的教程和文章,都是翻譯過來的,有很多寫非常不錯。 其實類似的資源不計其數,遇到問題時應該先到google上狂搜一圈。 重點想說些關于編譯器的東西,不了解它,在交叉編譯環境下編譯程序就寸步難行了,這無非是因為交叉編譯環境下目標板編譯器所處的寄人籬下的悲慘環境。想想在linux下將myprogram.c編譯鏈接成應用程序myprogram,最簡單的一句gcc –o myprogram myprogram.c 就可以了。(其實在諸如VC下你也可以找到類似的命令,集成開發環境只不過替你來調用它了)。一切看起來天經地義。 但試著把/usr/include路徑改一個名字(比如改成stupid_include),再這樣編譯一下,會發現程序中被< >引用的頭文件(比如#include gcc –I/usr/stupid_include –o myprogram myprogram.c 會發現錯誤信息沒了,一切又恢復了往日的寧靜,頓時明白,不用環境變量,通過參數,同樣可以將這些信息告訴編譯器。 返回來說說你的目標編譯器,雖然占用了人家的地盤,編譯器,頭文件,庫文件,一個都不少,但你要編一個程序編譯器照樣發暈,因為沒有環境變量告訴它自己需要的頭文件和庫文件在哪里。看來只有兩種辦法,一個是搶占了主機的環境變量改成自己的(整個兒一個土匪),或者在編譯時加上必要參數(還是這樣紳士一些),告訴編譯器需要的文件的位置。(除此之外,還有其他一些參數也是如此)。 從源程序到可執行文件根據情況不同可能分好幾步,一般每一步可能都會有一個應用程序實現,像gnu提供的arm開發工具鏈其實就是這么一組程序。提供從編譯到鏈接到格式轉化的全套服務。你可以用arm-elf-gcc命令一步到底直接產生可執行文件(其實也是在自己的任務完成后調用下一個程序),也可以每一步加上自己的參數,只作自己的事。 編譯器的主要參數的使用下次將程序的移植時再講。這里想說一下編譯器產生應用程序的幾個主要步鄹,講這個問題的原因還是很多人無法區分諸如編譯和鏈接,不用問,這一切還是IDE集成開發環境惹的禍。有人會說,IDE招你惹你了,你老貶它。其實不然,首先以上說的東西一般在IDE的project菜單下的option或build option中找到,只是一般不用管罷了。另一個方面,IDE就像是傻瓜照相機,很多工作他都幫你完成了,使用簡單。但如果要做攝影師的話,你就少不了要對每一個細節都了解。其實編譯程序也是一樣。(你可以對優化,警告級,宏定義等諸多選項進行自己的選擇)。以下是幾個主要步鄹:(以下有些我也不確認,如發現問題,請及時糾正。 (1) 預編譯。 主要工作就是處理所有#開頭的,包括頭文件。以前搞不清頭文件和可執行文件有沒有什么聯系(因為總看見兩個文件名字取一樣的),現在知道,他們之間沒有任何聯系。在預編譯結束后,頭文件的使命就結束了。在下一次介紹不同平臺程序移植時可以看到,預編譯有時非常有用。 (2) 編譯。編譯應該是最主要的一步,就是將源文件生成CPU能識別的語言,一般是 后綴為.o的目標文件,應該說,此時的文件就已經可以執行了。當然這個時候外部函數等外部符號都沒有引入,對于被編譯程序來說,這些外部符號還只是留一個倩影,壓根兒不知它在不在。你可以在你的程序里調用一個不存在的函數,甚至都不用聲明,在編譯階段,很多編譯器只是給個警告。只有在鏈接時才會報錯。(呵呵,夠弱智!) (3) 鏈接:鏈接才是清帳的時候,以前在程序里用到的外部符號都要把真正的東西交出來。你可以指定需要連接在一起的目標文件,也可以告訴編譯器庫文件的名字和路徑(指定方法下次講)。編譯器會去找,需要注意的是,庫的指定需要注意順序。首先,如果不同的庫里有同名函數,并且該函數被調用,那么在前面的就被鏈接進去了,這一點對于頭文件路徑的指定也適用,如果你自己的頭文件和系統頭文件相同,并且你的頭文件路徑在系統頭文件路徑前面,你的頭文件就會代替頭文件。庫文件是由相應的程序(linux下是ar命令)將需要被添加到庫里的目標文件(該文件是編譯階段生成的)組織起來生成檔案文件,同時可以建立一個檢索,檢索內容為所包含的目標文件中定義的符號。也就是說,庫文件并不是必須的,但它為經常使用的目標文件中的函數提供了快速的檢索機制。 以上就是主要的步鄹,當然除此之外,還有一些用于格式轉換的工具等。不一一介紹。知道編譯器的細節對于程序的開發和移植都是很有好處的。 程序開發過程中調試也是至關重要,因為可以先在主機上調試,所以可以使用linux下的gdb,(有點像dos 下的debug)。但是只是用到了皮毛,還有一個專用于宿主機模式的調試工具gdbserver,一直沒時間研究,希望用過的大俠多發些文章鋪路。 另外還會遇到如何作ramdisk,如何讓系統啟動自己的程序,這些都太linux了,沒接觸過linux的人會暈,為了大家的健康,就不講了,遇到問題可以給我email,大家一起討論。 4.不同平臺間程序的移植--簡單程序的移植 研究程序移植的那兩周是最痛苦的兩周,沒有太多可以借鑒的東西,只能摸黑向前走,于是更加堅定決心要整理些東西給后來的弟兄。不過話說回來,各位弟兄別被我前面說的嚇倒,只要搞清你要作什么,程序移植其實是比較簡單的事情。 首先列出一些問題: (1) X86上運行的程序能不能在51單片機上運行,為什么,有沒有可能,如果可以,應該做哪些工作才可以實現。 (2) 相同CPU平臺,DOS的程序為什么可以在windows下運行,能不能在linux下運行,為什么,作什么工作可能實現。 為什么可以移植程序,為什么要移植程序? 程序可以移植首先要感謝開發出高級語言的大牛們,記住,無論多么漂亮的代碼經過編譯以后都要變成CPU可以識別的機器語言,而幾乎一千種CPU說著一千種語言。為保證大家有共同語言,規定一種高級語言――高級語言。每一個CPU派出自己的翻譯――編譯器。這個翻譯精通兩國語言,高級語言和自己的語言。(由此已經可以看出編譯工具在程序移植中的重要性)。只要程序沒有硬件上的約束,可以說這種溝通是無極限的,甚至于不同操作系統平臺。(操作系統也是程序,也可以移植嘍)舉例:在x86的windows下用VC(或TC,BC)編一個c程序實現i=i+1,絲毫不改就可以用51的C編譯器重新編譯并在 51單片機上運行。一次小型的移植就結束了。 可以移植已有的程序還要感謝開放源代碼的弟兄,沒有這些C文件和H文件讓你重新編譯一下,怎么在你的CPU上跑?其實不止這些,后面還會看見開源組織的牛人專為程序可移植性所作的專門的工作。 那么為什么要移植程序? 問這問題就像問地上有個錢包為什么要撿一樣,答案不言而喻。現成的東西為什么不要。當然,移植程序可沒有撿錢包那么簡單,尤其是第一次,后面會說一些移植之前應該考慮的問題。(就像現在地上有個錢包也千萬別上去就揣自己兜里,說不定就是套)。另一方面,你給我你寫好的程序讓我拿去用,我還要考慮一下,或許里頭問題多的還不如自己寫一個。我這里所說的可移植的程序應該是維護比較好,比較成熟的源代碼(像我后面的所說的UCD-SNMP),目前的開放源代碼運動決不僅僅是把自己的程序公開就行了,而是有了一套成熟完整的版本控制,BUG報告和PATCH提交流程。這樣的代碼才有更大的使用價值。 什么時候可以考慮移植程序? 在基于嵌入式操作系統進行開發時,具有一定規模的程序都可以到網上查一查都沒有成熟的源代碼可用。前面已經說到,程序的移植最終只針對CPU,其實和操作系統沒什么關系,但另一方面,因為代碼中可能會使用一些庫函數,這些庫會包括C語言標準庫和操作系統提供的API(應用程序接口)庫。假設源代碼中只包括C標準庫,那么該程序就可以跨操作系統去移植。例如hello world程序中使用了printf,因為該函數是C標準函數,所以在X86上使用TC(BC或VC)可以直接編譯運行,在ARM+uClinux平臺下也一樣,但如果程序中調用了vfork函數,那么只有linux一脈相承的操作系統支持這種特殊服務了,在window或dos操作系統下無法直接編譯該程序了。只能找該操作系統支持的類似的功能來實現。再進一步,硬件上的生理缺陷也會為移植帶來麻煩,S3C4510B不支持MMU,在其上運行的 uClinux也不提供和MMU有關的服務(其實uClinux本身可以支持MMU),于是在移植前相關的函數(比如FORK)都要被替代掉(使用 VFORK)。好在uClinux和linux提供的應用接口大部分還是相同的。所以這樣的工作還可以承受。 由上可知,如果是在各種嵌入式linux(除了uClinux以外,還有好幾種)平臺上開發,那么針對該平臺以及linux平臺上的源代碼都可以使用,但是要牢記他們之間的差異。在我的系統中需要實現網絡監控,所以想使用snmp協議,該協議和http,ftp一樣屬于應用層的成熟協議,專用于網絡管理。目前已經有一些針對該協議成熟的代碼,最有名的是ucd-snmp,不光軟件本身功能強大,可移植性也比較好,在linux,unix等平臺上都可以移植,于是決定將它移植到ARM+uClinux平臺上(別看現在說的這么輕松,當時接這活時都有點哆嗦)。 簡單總結一下,移植應用程序的前提是有源代碼,移植的關鍵工具是編譯器,源代碼中和硬件平臺相關的東西越少越好(這里主要指使用了匯編,或做了針對自己平臺的事,比如將指針指向特定地址然后操作),另一方面,如果該程序是基于某個操作系統(利用了操作系統提供的特殊服務,即API),要看自己的操作系統是否提供了相關服務。 下面簡單列出一些我認為移植時需要考慮的問題: (1) 自己的操作系統的特點以及在當前版本下支持的特性。 例如:uClinux不支持MMU,同樣就無法支持相應的特性。 (2) 硬件資源。 因為嵌入式系統資源比較緊張,硬件資源考慮必須要周全: (1) 軟件存儲空間的大小 這一般要等用目標編譯器重新編譯完以后可能才會知道,所以只能大概估算,但千萬不要看這個程序在linux下只有幾十k,就認為程序很小,這是因為linux下程序多時使用動態庫,而在嵌入式系統中,很有可能是把用到的庫都鏈接在一起,所以程序的尺寸會大大增加。 (2) 程序運行空間。. (3) 硬件以及相應的驅動是否完備 以上工作應該盡量做,但有時事先無法把握,只能聽天由命了(有沒有搞錯!!) 可能有人已經要暈菜了,振奮一下大家,如果找到了好的源代碼(可移植性好),那么剩下的如要工作就是玩轉你的編譯器,只要你能順利的把源代碼用你的編譯器重新編譯一下。90%的工作就完成了(不是嗎) 上回已經介紹了一些編譯器方面的東西,下面針對我的ARM編譯器的具體參數來講解一些編譯器主要參數的設置。 加入我已經有了hello.c,在x86的linux平臺下編譯鏈接一下。 gcc –c hello.c 產生.o gcc –o hello hello.o 產生可執行文件 上回說過,主機編譯器參數都有環境變量保存,所以看起來很簡單。這里我故意分兩個步鄹。 下面看一下用我的編譯器編這個程序(心臟不好的先吃藥)。 arm-elf-gcc -Iroot/uClibc/include -msoft-float -mcpu=arm7tdmi -fomit-frame-pointer -fsigned-char -mcpu=arm7tdmi -Os –Wall -DEMBED -D_uclinux_ -c hello.c 這只是編譯,將參數逐一講解。 Arm-elf-gcc 是gnu的arm編譯工具 1)Include地址:參數:-I 值:root/uClibc/include(這是在主機上我的uClinux的頭文件路徑) 用法:-I root/uClibc/include -I參數保證后面的頭文件路徑在搜索系統頭文件路徑前被搜索從而有可能替代系統的頭文件,如果有多個這樣的參數,則搜索的順序是從左到右,然后是系統的頭文件。 2)-m 是針對CPU的選項。 -mcpu=arm7tdmi 說明CPU類型 -msoft-float 產生包含浮點庫的輸出 -fsigned-char 讓char類型有符號 -fomit-frame-pointer 對所有不需要幀指針的函數都不將其保存在寄存器中。 3) -Os –Wall -Wall:所有警告都顯示 Os:優化尺寸,該選項使能所有所有不增加尺寸的O2優化,并且進一步根據尺寸優化 4) = -DEMBED -D_uclinux_ -D: 將-Dmacro 后的macro定義為字符串1。 以下是鏈接: arm-elf-ld -L/root/uClibc/lib -L/usr/local/gnu/arm-elf/lib -L/usr/local/gnu/lib/gcc-lib/arm-elf/3.0.1 -elf2flt –o hello /root/uClibc/lib/crt0.o /usr/local/gnu/lib/gcc-lib/arm-elf/3.0.1/crtbegin.o hello.o /usr/local/gnu/lib/gcc-lib/arm-elf/3.0.1/crtend.o -lc -lgcc –lc 其中 1) 鏈接工具: arm-elf-ld 2) -L指明需要鏈接的庫的路徑,用法和-I一樣,自己的庫的路徑也可以在這里加入。 -L/root/uClibc/lib -L/usr/local/gnu/arm-elf/lib -L/usr/local/gnu/lib/gcc-lib/arm-elf/3.0.1 3) –o 后面緊跟生成的最終的文件名 4)/root/uClibc/lib/crt0.o /usr/local/gnu/lib/gcc-lib/arm-elf/3.0.1/crtbegin.o OBJECTS.o /usr/local/gnu/lib/gcc-lib/arm-elf/3.0.1/crtend.o 這是需要鏈接在一起的.o文件 5) -lc -lgcc –lc -l 后面緊跟的是需要鏈接的庫的名字,一般庫的名字是libxxx.a,使用時為-lxxx即可,不加lib和.a。還要注意位置,自己的庫文件應該加在他的庫前面。 編譯通過后,移植就算完成了,對于比較小的源代碼都可以這樣,即先分析他的編譯選項(用到了那些頭文件,庫文件等),然后用自己的編譯器對照相應參數重新編譯一下就行了。 當然這只是簡單程序的移植,復雜案例在下一次講吧。 |