博客
有關 EMQX 水平可擴展性的挑戰與對策 - MQTT Broker 集群詳解(三)
|
在這篇文章中,我們將介紹 MQTT Broker 集群在可擴展性方面的一些改進。 我們將主要關注 EMQX 內部使用的數據庫引擎,以及它在 EMQX 5.0 版本中是如何改進的。
在開始本文之前,我們需要了解 EMQX 集群中是數據是如何復制的:EMQX broker 將主題和客戶端的運行時信息存儲在 Mnesia 數據庫中,有助于跨集群復制數據。
Mnesia 簡介Mnesia 是一個開源數據庫管理系統,由愛立信公司開發作為開放電信平臺( Open Telecom Platform )的一部分,最初是用來處理 ISP 級電信交換機中的配置和運行時數據。EMQX 4.3 之前的版本使用其來存儲各種運行時數據,例如主題、路由、ACL 規則、告警等等。
MySQL、Postgres、MongoDB 等數據庫以及 Redis 和 memcached 等內存存儲大家應該都非常熟悉,對 Mnesia 則可能不甚了解。但它確實有其獨特的優勢,可將上述產品的許多功能集成到一個簡潔的應用程序中。
Mnesia 有一個相當學術的定義:一個嵌入式、分布式、事務型的 noSQL(非關系型)數據庫。聽起來有些復雜,我們接下來將逐一為大家解釋。
嵌入式MySQL 和 Postgres 等最廣泛使用的數據庫普遍采用客戶端—服務器模式:數據庫在單獨的進程中運行(通常在專用服務器上),業務應用程序通過網絡或 UNIX 域套接字發送請求并等待答復,通過這種方式來與數據庫交互。這種模式在很多方面都很方便,因為它允許將業務邏輯與存儲分開并單獨管理。 但同時也有一些缺點:與遠程進程交互不可避免地會增加每個請求的延遲。
相反,嵌入式數據庫與業務應用程序則在相同的進程中運行。sqlite 是一個典型的嵌入式數據庫的例子。Mnesia 也屬于這一類:它與其他 EMQX 應用程序在同一進程中運行。 從 Mnesia 表中讀取數據可以像讀取局部變量一樣快,因此我們可以在熱點中讀取數據庫數據而不會影響性能。
分布式我們之前提到過 Mnesia 是一個分布式數據庫,這意味著數據表被網絡復制到不同的物理位置。對于分布式數據庫,如果節點之間不共享任何物理資源(如 RAM 或磁盤),而是在應用程序級別進行協調,這種類型稱為無共享架構 (SN)。 這種類型通常是首選,因為它不需要任何專門的硬件,并且可以水平擴展。
Mnesia 應用程序與 EMQX 一起運行,有助于通過 Erlang 分發協議跨集群中的所有節點復制表更新。 這意味著業務應用程序可以在本地讀取更新的數據。它還有助于提升容錯性能:只要集群中有一個節點處于活動狀態,數據就是安全的。EMQX 依靠此功能實現跨集群復制路由信息。
事務型Mnesia 支持 ACID 事務,這是嵌入式數據庫的一個非常獨特的功能。這意味著可以將多個讀取和更新操作組合在一起。一個 Mnesia 事務具有原子性(必須完整或無任何效力)、一致性(盡管保證比 Postgres 更寬松)、隔離性(不影響其他事務)和持久性。所有這些保證都在整個集群中保留。
在數據一致性關鍵場景中,EMQX 采用 Mnesia 事務。
NoSQL傳統的關系型數據庫使用一種稱為 SQL 的特殊查詢語言與數據庫進行交互,這種數據庫通常使用 ORM(對象關系映射) 來加快開發速度。 另一方面,Mnesia 沒有專門的查詢語言:它使用 Erlang(或 Elixir)作為查詢語言,因此不需要 ORM。 它直接使用 Erlang 術語進行查詢操作,與業務邏輯的集成非常順暢。
架構在 Mnesia 集群中,所有節點都是平等的。 每個節點都可以存儲任何表的副本、啟動事務并訪問這些表。 Mnesia 集群使用全網狀拓撲:每個節點都與集群中的所有其他節點對話。 每個事務都被復制到集群中的所有節點,如下圖所示:
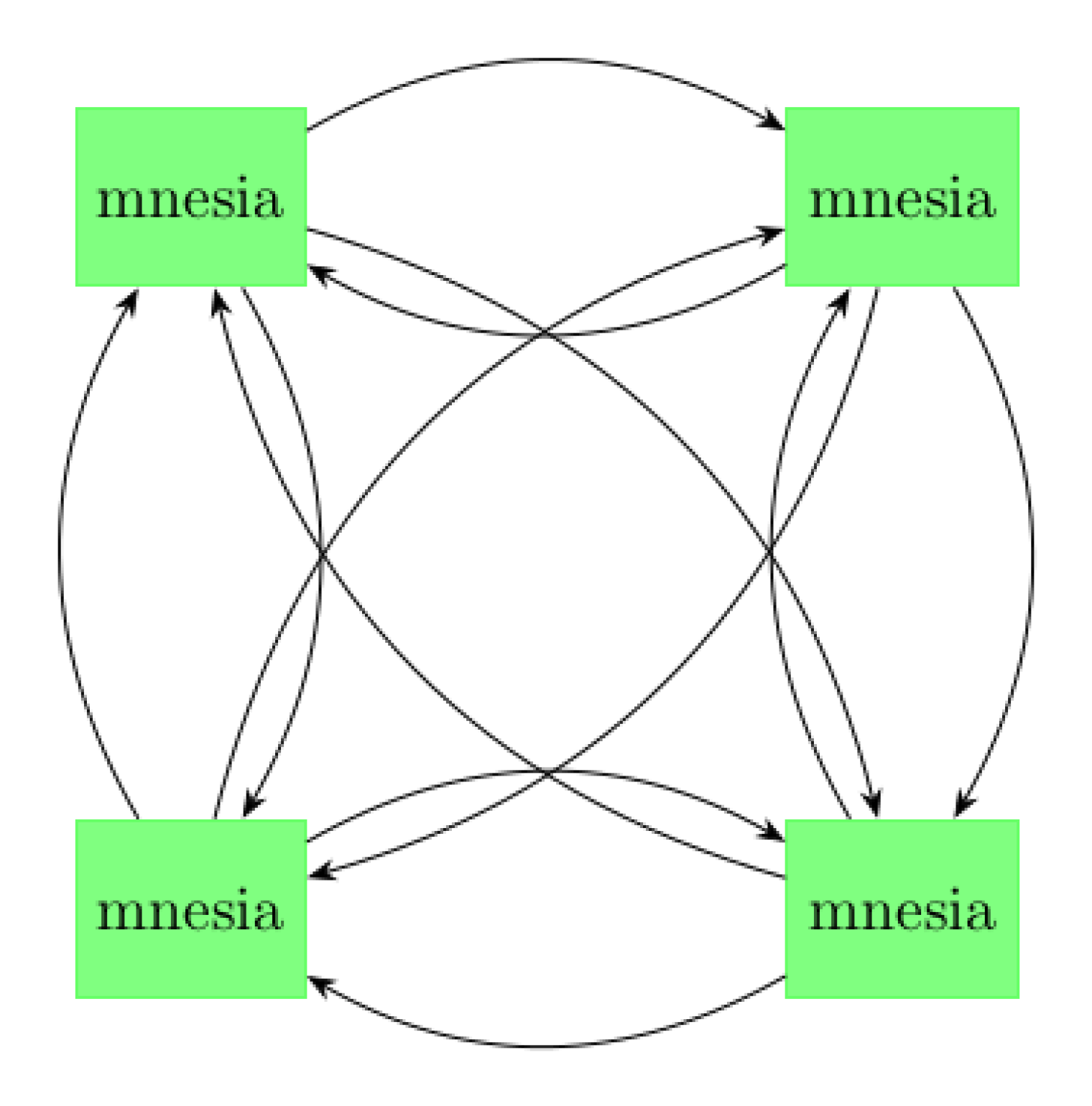
Mnesia 集群
針對 CAP 原則(在一致性、可用性、分區容錯性三個要素中選擇兩個),Mnesia 默認為 AP(可用性、分區容錯性)。
挑戰綜上所述,Mnesia 數據庫有一系列獨特的功能,并都在 EMQX 中得到了使用。現在,我們要談談它的缺點以及我們改進它的原因。
盡管 Mnesia 與硬件無關,但它最初的開發考慮了特定的集群架構:一組服務器,通過快速、低延遲的局域網實現互連。
在理想條件下,網狀拓撲結構可以減少事務復制延遲:節點之間的所有通信都可以并行完成,無需任何中介。 然而,它限制了集群的水平可擴展性,因為節點之間的鏈接數量和節點數量之間是平方關系。隨著節點數量的增加,保持所有節點完全同步的成本越來越高,事務的性能也會下降。
節點的同等性質和傳統的集群范式疊加后,使得更換單個節點變得容易,但是可以同時加入集群的節點數量受到限制。
于是我們就面臨這樣一個局面:集群部署在地理冗余的云環境中,一切都是動態的和暫時的,節點在自動擴展組中運行,我們希望它們一直在波動狀態。
為了應對這些挑戰,我們對 Mnesia 進行了擴展,稱之為 Mria。
對策:Mria 的引入Mria 是 Mnesia 的開源擴展版本,它為 Mnesia 帶來了最終一致性。
Mria 從全網狀拓撲架構轉變為網狀+星型拓撲架構。 每個節點承擔兩個角色之一:核心(core)或復制者(replicant)。
核心(core)節點的行為很像常規的 Mnesia 節點:它們以全網狀連接,每個節點都可以發起寫事務、持有鎖等。核心節點很大程度上都是靜態和持久的。
另一方面,復制(replicant)節點不參與事務。它們連接到某一個核心節點,并被動地從中復制事務。這意味著不允許復制節點自行執行任何寫操作。相反,它們要求核心節點代表它們更新數據。同時,它們擁有數據的完整本地副本,因此讀取訪問速度也同樣快。
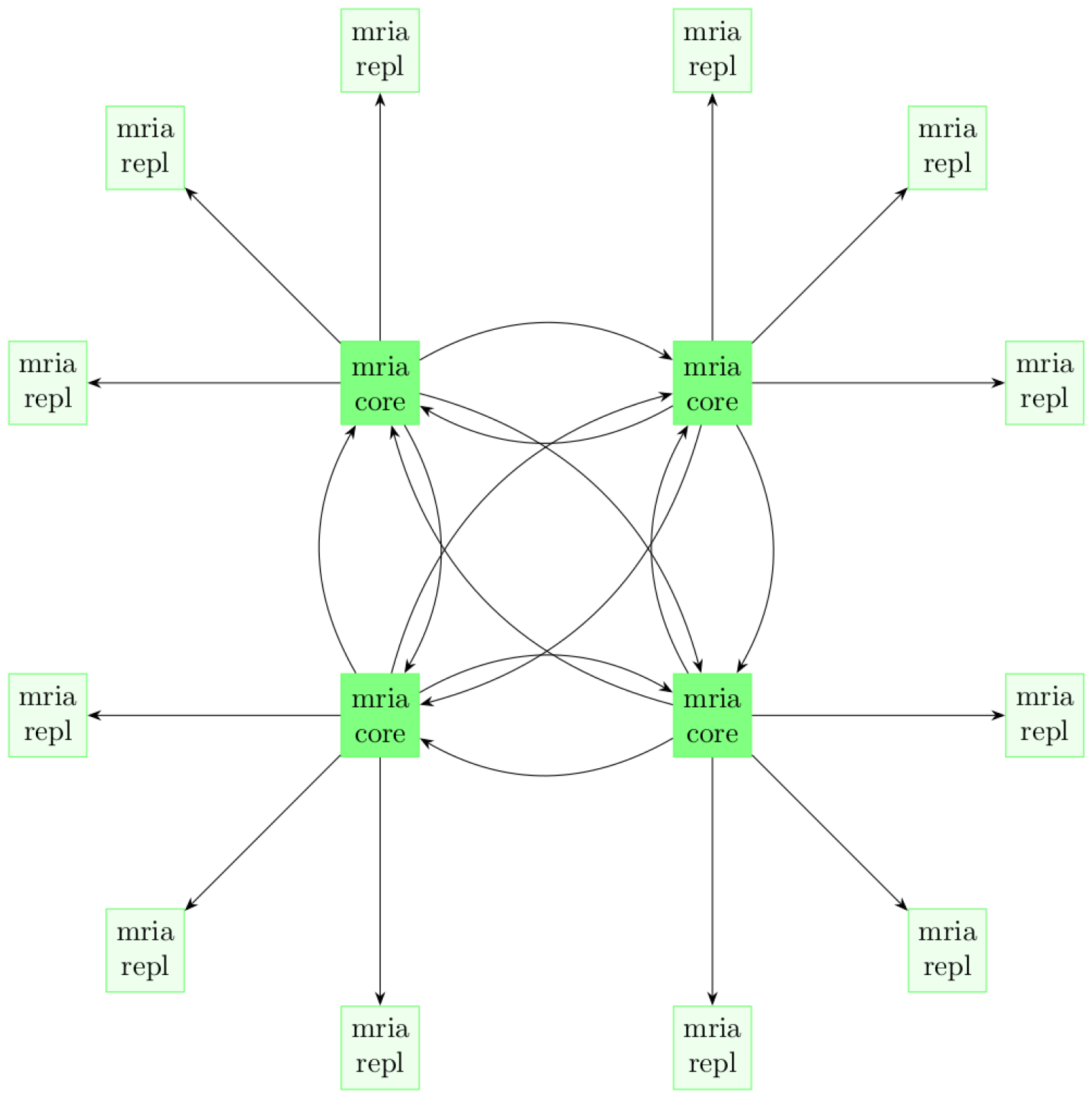
Mria 集群
可以將 Mria 看作是客戶端-服務器和嵌入式數據庫的組合:通過服務器寫入,但在本地讀取。
這種集群拓撲架構解決了兩個問題:
- 水平可擴展性
- 支持集群自動擴展
由于復制節點不參與寫入,因此當向集群添加更多復制節點時,事務延遲不會受到影響,從而允許創建更大的 EMQX 集群。
此外,復制節點被設計為暫時的。 添加或刪除它們不會改變數據冗余,因此可以將它們放在自動擴展組中,從而實現更好的 DevOps 實踐。
在下一篇文章中,我們將更詳細地討論如何配置 EMQX 來充分 Mria 的優勢。
本系列中的其它文章原創文章,作者:EMQ,如若轉載,請注明出處:https://www.emqx.com/zh/blog/mqtt-broker-clustering-part-3-challenges-and-solutions-of-emqx-horizontal-scalability




